Vnútri BERT: Ako dvojstranné kódovacie reprezentácie z transformátorov redefinujú spracovanie prirodzeného jazyka a poháňajú ďalšiu generáciu aplikácií AI
- Úvod do BERT: Pôvod a prelomové objavy
- Ako BERT funguje: Veda za dvojstrannými transformátormi
- Predtréning a jemné doladenie: Dvojstupňový učebný proces BERT
- BERT vs. Tradičné NLP modely: Čo ho odlišuje?
- Reálne aplikácie: BERT vo vyhľadávaní, chatbotov a ďalších oblastiach
- Obmedzenia a výzvy: Kde BERT zaostáva
- Budúcnosť BERT: Inovácie, varianty a čo nás čaká
- Zdroje a odkazy
Úvod do BERT: Pôvod a prelomové objavy
Dvojstranné kódovacie reprezentácie z transformátorov (BERT) predstavujú významný míľnik vo vývoji spracovania prirodzeného jazyka (NLP). BERT, ktorý bol predstavený výskumníkmi z Google AI Language v roku 2018, zásadne zmenil spôsob, akým stroje chápu jazyk, využitím sily hlbokých dvojstranných transformátorov. Na rozdiel od predchádzajúcich modelov, ktoré spracovávali text buď zľava doprava, alebo sprava doľava, architektúra BERT umožňuje zohľadniť celý kontext slova tým, že zisťuje jeho okolie zľava aj sprava súčasne. Tento dvojstranný prístup umožňuje jemnejšie chápanie jazyka, zachytávajúce subtílne vzťahy a významy, ktoré jednosmerné modely často prehliadajú.
Pôvod BERT je zakorenený v architektúre transformátora, ktorú prvýkrát predstavil Vaswani et al. (2017), ktorá sa spolieha na mechanizmy seba-pozornosti na spracovanie vstupných sekvencií súčasne. Predtréning na masívnych korpusoch, ako sú Wikipedia a BooksCorpus, umožňuje BERT-u učiť sa všeobecné jazykové reprezentácie, ktoré môžu byť jemne doladené na širokú škálu downstream úloh, vrátane odpovedania na otázky, analýzy sentimentu a rozpoznávania pomenovaných entít. Uvoľnenie BERT nastavilo nové benchmarky naprieč viacerými úlohami NLP, prekonávajúc predchádzajúce špičkové modely a inšpirujúc vlnu výskumu v oblasti architektúr založených na transformátoroch.
Prelomy, ktoré BERT dosiahol, nielenže posunuli akademický výskum vpred, ale tiež viedli k praktickým zlepšeniam v komerčných aplikáciách, ako sú vyhľadávače a virtuálni asistenti. Jeho open-source uvoľnenie sprístupnilo silné jazykové modely, čo podporuje inováciu a spoluprácu v celom spoločenstve NLP.
Ako BERT funguje: Veda za dvojstrannými transformátormi
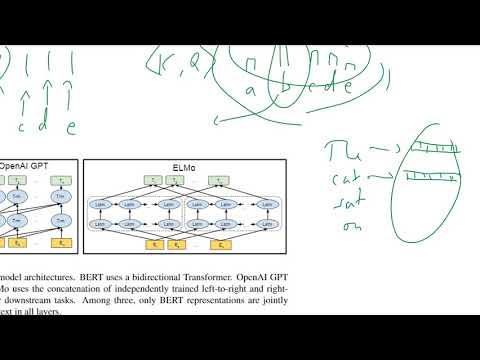
Hlavná inovácia BERT spočíva v použití dvojstranných transformátorov, ktoré zásadne menia spôsob, akým jazykové modely chápu kontext. Na rozdiel od tradičných modelov, ktoré spracovávajú text buď zľava doprava alebo sprava doľava, BERT využíva architektúru transformátora na analýzu všetkých slov v vete súčasne, pričom zohľadňuje predchádzajúce aj nasledujúce slová. Tento dvojstranný prístup umožňuje BERT-u zachytávať jemné vzťahy a závislosti v jazyku, čo vedie k hlbšiemu pochopeniu významu a kontextu.
Veda, ktorá stojí za dvojstrannosťou BERT, je zakorenená v jeho predtréningových úlohách: Masked Language Modeling (MLM) a Next Sentence Prediction (NSP). V MLM sú náhodne vybrané slová vo vete maskované a model sa učí predpovedať tieto maskované tokeny z ohľadom na celý kontext na oboch stranách. To kontrastuje s predchádzajúcimi modelmi, ktoré mohli používať iba čiastočný kontext, čo obmedzilo ich porozumenie. NSP, na druhej strane, trénuje BERT, aby chápal vzťah medzi pármi viet, čo ďalej zlepšuje jeho schopnosť chápať kontext a koherenciu.
Architektúra BERT je založená na transformátorovom kódovači, ktorý využíva mechanizmy seba-pozornosti na vážení dôležitosti každého slova v porovnaní s ostatnými vo vstupe. To umožňuje BERT-u modelovať zložité jazykové javy, ako sú polysemia a dlhodobé závislosti. Výsledkom je model, ktorý dosahuje špičkovú výkonnosť v širokej škále úloh spracovania prirodzeného jazyka, vrátane odpovedania na otázky a analýzy sentimentu. Pre podrobný technický prehľad sa pozrite na pôvodný dokument od Google AI Language a oficiálnu dokumentáciu od Google Research.
Predtréning a jemné doladenie: Dvojstupňový učebný proces BERT
Remarkabilná výkonnosť BERT v úlohách spracovania prirodzeného jazyka je do značnej miery pripisovaná jeho inovatívnemu dvojstupňovému učebnému procesu: predtréningu a jemnému doladeniu. Počas fázy predtréningu je BERT vystavený obrovskému množstvu neoznačeného textu, učí sa všeobecné jazykové reprezentácie prostredníctvom dvoch samonáhodných úloh: Masked Language Modeling (MLM) a Next Sentence Prediction (NSP). V MLM sú náhodne vybrané slová vo vete maskované a model sa učí predpovedať tieto maskované tokeny na základe ich kontextu, čo umožňuje hlboké dvojstranné chápanie. NSP zase trénuje BERT, aby určoval, či jedna veta logicky nasleduje za druhou, čo je kľúčové pre úlohy zahŕňajúce vzťahy medzi vetami (Google Research).
Po predtréningu prechádza BERT jemným doladením na konkrétne downstream úlohy, ako sú odpovedanie na otázky, analýza sentimentu alebo rozpoznávanie pomenovaných entít. V tomto štádiu sa predtrénovaný model ďalej trénuje na menšom, označenom dátovom súbore prispôsobenom cieľovej úlohe. Architektúra zostáva väčšinou nezmenená, ale podľa potreby sa pridávajú vrstvy špecifické pre úlohu (napr. klasifikačné hlavy). Jemné doladenie typicky vyžaduje iba niekoľko epoch a relatívne málo údajov, pretože model už počas predtréningu nadobudol robustné chápanie jazyka. Tento dvojstupňový prístup umožňuje BERT-u dosahovať špičkové výsledky v širokej škále benchmarkov NLP, čo dokazuje efektivitu transferového učenia v jazykových modeloch (Google AI Blog).
BERT vs. Tradičné NLP modely: Čo ho odlišuje?
BERT (Dvojstranné kódovacie reprezentácie z transformátorov) predstavuje významný odklon od tradičných modelov spracovania prirodzeného jazyka (NLP), predovšetkým vďaka svojmu dvojstrannému pochopeniu kontextu a architektúre založenej na transformátoroch. Tradičné modely NLP, ako sú modely typu bag-of-words, n-gram modely a skoršie slová reprezentujúce embeddings ako Word2Vec alebo GloVe, spravidla spracovávajú text v jednosmernom alebo kontextovo nezávislom režime. Napríklad modely ako Word2Vec generujú vektory slov výlučne na základe lokálnych kontextových okien, a rekurentné neurónové siete (RNN) spracovávajú sekvencie buď zľava doprava alebo sprava doľava, čo obmedzuje ich schopnosť zachytávať plný kontext viet.
Naopak, BERT využíva architektúru transformátora, ktorá mu umožňuje zohľadniť súčasne aj ľavý, aj pravý kontext pre každé slovo vo vete. Tento dvojstranný prístup umožňuje BERT-u generovať bohatšie, kontextovo citlivé reprezentácie slov, čo je obzvlášť výhodné pre úlohy vyžadujúce jemné pochopenie, ako je odpovedanie na otázky a analýza sentimentu. Okrem toho je BERT predtrénovaný na veľkých korpusoch pomocou cieľov maskovaného jazykového modelovania a predpovedania nasledujúcej vety, čo mu umožňuje naučiť sa hlboké sémantické a syntaktické znaky pred jemným doladením na konkrétne downstream úlohy.
Empirické výsledky preukázali, že BERT konzistentne prekonáva tradičné modely v širokej škále benchmarkov NLP, vrátane datasetov GLUE a SQuAD. Jeho architektúra a tréningová paradigma nastavili nové štandardy pre transferové učenie v NLP, umožňujúc praktikom dosahovať špičkové výsledky s minimálnymi úpravami architektúry špecifickými pre úlohy. Pre viac podrobností sa pozrite na pôvodný dokument od Google AI Language a oficiálny BERT GitHub repozitár.
Reálne aplikácie: BERT vo vyhľadávaní, chatbotov a ďalších oblastiach
Transformačný dopad BERT na spracovanie prirodzeného jazyka (NLP) je najviditeľnejší v jeho reálnych aplikáciách, najmä v vyhľadávačoch, chatbotoch a rôznych ďalších oblastiach. V oblasti vyhľadávania umožňuje BERT systémom lepšie chápať kontext a zámery za dopytmi používateľov, čo vedie k relevantnejším a presnejším výsledkom. Napríklad, Google integroval BERT do svojich vyhľadávacích algoritmov, aby zlepšil interpretáciu konverzačných dotazov, najmä tých, ktoré obsahujú predložky a jemné frázy. Tento pokrok umožňuje vyhľadávačom priradiť dopyty k obsahu spôsobom, ktorý bližšie zodpovedá ľudskému chápaniu.
V oblasti konverzačnej AI BERT výrazne zlepšil výkon chatbotov. Vďaka tomu, že využíva svoje hlboké dvojstranné kontextuálne schopnosti, môžu chatboty generovať koherentnejšie a kontextovo vhodné odpovede, čo zlepšuje spokojnosť a zapojenie používateľov. Spoločnosti ako Microsoft integrovali BERT do svojich platforiem konverzačnej AI, čím umožnili prirodzenejšie a efektívnejšie interakcie v službách zákazníkom a aplikáciách virtuálnych asistentov.
Okrem vyhľadávania a chatbotov bola architektúra BERT prispôsobená pre úlohy ako analýza sentimentu, klasifikácia dokumentov a odpovedanie na otázky. Jeho schopnosť byť jemne doladený pre konkrétne úlohy s relatívne malými datasetmi sprístupnila špičkové NLP, čo umožnilo organizáciám všetkých veľkostí nasadiť pokročilé schopnosti porozumenia jazyku. V dôsledku toho BERT naďalej poháňa inováciu naprieč odvetviami, od zdravotnej starostlivosti po financie, tým, že umožňuje strojom spracovávať a interpretovať ľudský jazyk s bezprecedentnou presnosťou a jemnosťou.
Obmedzenia a výzvy: Kde BERT zaostáva
Napriek svojmu transformačnému dopadu na spracovanie prirodzeného jazyka vykazuje BERT niekoľko pozoruhodných obmedzení a výziev. Jedným z hlavných problémov je jeho výpočtová náročnosť; ako predtréning, tak aj jemné doladenie BERT vyžadujú významné hardvérové zdroje, čo ho robí menej prístupným pre organizácie s obmedzenou výpočtovou infraštruktúrou. Veľká veľkosť modelu tiež vedie k vysokému spotrebe pamäti a pomalým časom inferencie, čo môže sťažovať nasadenie v reálnom čase alebo v obmedzených prostrediach (Google AI Blog).
Architektúra BERT je inherentne obmedzená na vstupné sekvencie fixnej dĺžky, obvykle obmedzenej na 512 tokenov. Toto obmedzenie predstavuje výzvy pre úlohy zahŕňajúce dlhšie dokumenty, pretože sú potrebné truncation alebo zložité stratégia rozdelenia, čo môže viesť k strate kontextu a zhoršeniu výkonu (arXiv). Okrem toho je BERT predtrénovaný na veľkých, generálnych korpusoch, čo môže viesť k suboptimálnemu výkonu na úlohách špecifických pre doménu, pokiaľ nie je vykonaná ďalšia adaptácia na doménu.
Ďalšou výzvou je neschopnosť BERT vykonávať uvažovanie alebo riešiť úlohy vyžadujúce znalosti o svete nad rámec toho, čo je prítomné v jeho tréningových údajoch. Model je tiež náchylný na protiútoky a môže produkovať zaujaté alebo bezvýznamné výstupy, odrážajúce zaujatosti prítomné v jeho tréningových údajoch (Národný ústav pre normy a technológie (NIST)). Ďalej zostáva interpretovateľnosť BERT obmedzená, čo sťažuje pochopenie alebo vysvetlenie jeho predpovedí, čo je významný problém pre aplikácie v citlivých oblastiach, ako je zdravotná starostlivosť alebo právo.
Budúcnosť BERT: Inovácie, varianty a čo nás čaká
Od svojho uvedenia na scénu Dvojstranné kódovacie reprezentácie z transformátorov (BERT) revolučne zmenili spracovanie prirodzeného jazyka (NLP), ale pole sa naďalej rýchlo vyvíja. Budúcnosť BERT je formovaná prebiehajúcimi inováciami, vznikom mnohých variantov a integráciou nových techník, aby sa adresovali jeho obmedzenia. Jedným z hlavných smerov je vývoj efektívnejších a škálovateľnejších modelov. Napríklad modely ako DistilBERT a TinyBERT ponúkajú ľahšie alternatívy, ktoré si zachovávajú veľkú časť výkonnosti BERT pri znížení výpočtových požiadaviek, čo ich robí vhodnými na nasadenie na okrajové zariadenia a v reálnych aplikáciách (Hugging Face).
Ďalším významným trendom je prispôsobenie BERT pre viacjazyčné a doménovo špecifické úlohy. Viacjazyčný BERT (mBERT) a modely ako BioBERT a SciBERT sú prispôsobené pre špecifické jazyky alebo vedecké domény, čo demonštruje flexibilitu architektúry BERT (Google AI Blog). Okrem toho sa výskum sústreďuje na zlepšenie interpretovateľnosti a robustnosti BERT, čo sa týka obáv o transparentnosť modelu a zraniteľnosť voči protivníckym útokom.
S pohľadom do budúcnosti je integrácia BERT s inými modalitami, ako sú vízia a reč, sľubnou oblasťou, čo sa ukazuje v modeloch ako VisualBERT a SpeechBERT. Navyše vzostup veľkorozmerných predtrénovaných modelov, ako sú GPT-3 a T5, inšpiroval hybridné architektúry, ktoré kombinujú silné stránky dvojstrannej kódovacej schopnosti BERT s generatívnymi schopnosťami (Google AI Blog). Ako výskum pokračuje, očakáva sa, že BERT a jeho nasledovníci budú zohrávať kľúčovú úlohu pri zvyšovaní schopností systémov AI v rôznych aplikáciách.
Zdroje a odkazy
- Google AI Language
- Vaswani et al. (2017)
- Google Research
- Národný ústav pre normy a technológie (NIST)
- Hugging Face