Внутри BERT: Как двунаправленные кодировочные представления от трансформеров переопределяют обработку естественного языка и обеспечивают новое поколение приложений ИИ
- Введение в BERT: Происхождение и достижения
- Как работает BERT: Научные основы двунаправленных трансформеров
- Предварительное обучение и адаптация: Двухэтапный процесс обучения BERT
- BERT против традиционных моделей NLP: Чем он отличается?
- Применение в реальном мире: BERT в поисковых системах, чат-ботах и не только
- Ограничения и вызовы: Где BERT не справляется
- Будущее BERT: Инновации, варианты и что дальше
- Источник и ссылки
Введение в BERT: Происхождение и достижения
Двунаправленные кодировочные представления от трансформеров (BERT) представляют собой значительное достижение в эволюции обработки естественного языка (NLP). Введенный исследователями из Google AI Language в 2018 году, BERT коренным образом изменил способ, которым машины понимают язык, используя мощь глубоких двунаправленных трансформеров. В отличие от предыдущих моделей, которые обрабатывали текст слева направо или справа налево, архитектура BERT позволяет учитывать полный контекст слова, одновременно рассматривая его окружение слева и справа. Этот двунаправленный подход позволяет более точно понимать язык, улавливая тонкие отношения и значения, которые односторонние модели часто пропускают.
Происхождение BERT коренится в архитектуре трансформеров, впервые представленной Vaswani и др. (2017), которая полагается на механизмы самообращения для обработки входных последовательностей параллельно. Обучаясь на огромных корпусах, таких как Википедия и BooksCorpus, BERT изучает общие представления языка, которые можно дообучить для широкого круга задач, включая ответы на вопросы, анализ настроений и выявление именованных сущностей. Выпуск BERT установил новые эталоны по множеству задач NLP, превзойдя предыдущие современные модели и вдохновив волну исследований в области архитектур на основе трансформеров.
Достижения, достигнутые BERT, не только продвинули академические исследования, но и привели к практическим улучшениям в коммерческих приложениях, таких как поисковые системы и виртуальные ассистенты. Его открытый исходный код демократизировал доступ к мощным языковым моделям, способствуя инновациям и сотрудничеству в сообществе NLP.
Как работает BERT: Научные основы двунаправленных трансформеров
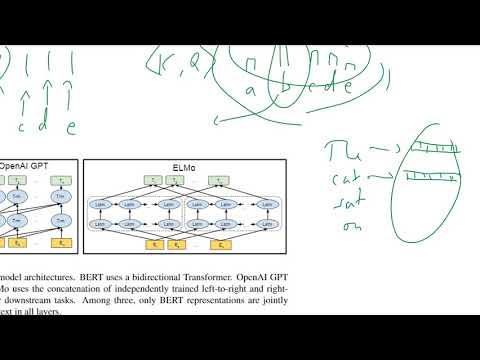
Основная инновация BERT заключается в его использовании двунаправленных трансформеров, которые коренным образом изменяют понимание контекста языковыми моделями. В отличие от традиционных моделей, которые обрабатывают текст слева направо или справа налево, BERT использует архитектуру трансформеров для одновременного анализа всех слов в предложении, учитывая как предшествующие, так и последующие слова. Этот двунаправленный подход позволяет BERT улавливать тонкие отношения и зависимости в языке, обеспечивая более глубокое понимание значения и контекста.
Научные основы двунаправленности BERT коренятся в его задачах предварительного обучения: Моделировании маскированного языка (MLM) и Предсказании следующего предложения (NSP). В MLM случайные слова в предложении маскируются, и модель обучается предсказывать эти маскированные токены, учитывая весь контекст с обеих сторон. Это контрастирует с предыдущими моделями, которые могли использовать только частичный контекст, что ограничивало их понимание. NSP, с другой стороны, обучает BERT понимать отношения между парами предложений, что еще больше усиливает его понимание контекста и связности.
Архитектура BERT основана на кодировщике трансформеров, который использует механизмы самообращения для оценки важности каждого слова относительно других в входных данных. Это позволяет BERT моделировать сложные лингвистические явления, такие как полисемия и долгосрочные зависимости. Результат — модель, которая демонстрирует современные достижения в большом диапазоне задач обработки естественного языка, включая ответы на вопросы и анализ настроений. Для подробного технического обзора обратитесь к оригинальной статье от Google AI Language и официальной документации от Google Research.
Предварительное обучение и адаптация: Двухэтапный процесс обучения BERT
Замечательная производительность BERT в задачах обработки естественного языка во многом объясняется его инновационным двухэтапным процессом обучения: предварительным обучением и адаптацией. В предварительном обучении BERT подвергается обработке огромных объемов нелинейного текста, изучая общие языковые представления через две задачи с самообучением: модель маскированного языка (MLM) и предсказание следующего предложения (NSP). В MLM случайные слова в предложении маскируются, и модель обучается предсказывать эти маскированные токены на основе их контекста, позволяя глубоко понимать двунаправленно. NSP, с другой стороны, обучает BERT определять, следует ли одно предложение логически за другим, что имеет решающее значение для задач, связанных с отношениями между предложениями (Google Research).
После предварительного обучения BERT проходит адаптацию на конкретные целевые задачи, такие как ответы на вопросы, анализ настроений или выявление именованных сущностей. На этом этапе предварительно обученная модель дополнительно обучается на более мелком, размеченном наборе данных, подобранном под целевую задачу. Архитектура в основном остается неизменной, но по мере необходимости добавляются слои, специфичные для задач (например, классификационные головы). Адаптация обычно требует всего лишь нескольких эпох и относительно немного данных, так как модель уже приобрела надежное понимание языка во время предварительного обучения. Этот двухэтапный подход позволяет BERT достигать современных результатов в широком диапазоне эталонов NLP, демонстрируя эффективность переноса обучения в языковых моделях (Google AI Blog).
BERT против традиционных моделей NLP: Чем он отличается?
BERT (двунаправленные кодировочные представления от трансформеров) представляет собой значительное отступление от традиционных моделей обработки естественного языка (NLP), в первую очередь благодаря его двунаправленному пониманию контекста и архитектуре на основе трансформеров. Традиционные модели NLP, такие как bag-of-words, n-gram модели и ранее использовавшиеся word embeddings, такие как Word2Vec или GloVe, обычно обрабатывают текст в единичном направлении или независимо от контекста. Например, такие модели, как Word2Vec, генерируют векторы слов исключительно на основе локальных контекстных окон, а рекуррентные нейронные сети (RNN) обрабатывают последовательности либо слева направо, либо справа налево, что ограничивает их способность захватывать полный контекст предложения.
В отличие от этого, BERT использует архитектуру трансформеров, которая позволяет ему одновременно учитывать как левый, так и правый контекст для каждого слова в предложении. Этот двунаправленный подход позволяет BERT генерировать более богатые, чувствительные к контексту представления слов, что особенно выгодно для задач, требующих тонкого понимания, таких как ответы на вопросы и анализ настроений. Более того, BERT предварительно обучается на больших корпусах с использованием задач маскированного моделирования языка и предсказания следующего предложения, что позволяет ему изучать глубокие семантические и синтаксические характеристики, прежде чем адаптироваться к конкретным задачам.
Эмпирические результаты показали, что BERT постоянно превосходит традиционные модели в широком диапазоне эталонов NLP, включая наборы данных GLUE и SQuAD. Его архитектура и парадигма обучения установили новые стандарты для переноса обучения в NLP, позволяя практикам достигать современных результатов с минимальными изменениями архитектуры, специфичными для задач. Для получения более подробной информации обратитесь к оригинальной статье от Google AI Language и официальному репозиторию BERT на GitHub.
Применение в реальном мире: BERT в поисковых системах, чат-ботах и не только
Трансформационное влияние BERT на обработку естественного языка (NLP) наиболее очевидно в его реальных приложениях, особенно в поисковых системах, чат-ботах и различных других областях. В поиске BERT позволяет системам лучше понимать контекст и намерение за пользовательскими запросами, приводя к более актуальным и точным результатам. Например, Google интегрировал BERT в свои поисковые алгоритмы для улучшения интерпретации разговорных запросов, особенно тех, которые содержат предлоги и тонкие формулировки. Это достижение позволяет поисковым системам сопоставлять запросы с содержанием таким образом, который более точно отражает человеческое понимание.
В области разговорного ИИ BERT значительно улучшил производительность чат-ботов. Используя свою глубокую двунаправленную контекстную информацию, чат-боты могут генерировать более согласованные и контекстуально уместные ответы, повышая удовлетворенность и вовлеченность пользователей. Компании, такие как Microsoft, внедрили BERT в свои платформы разговорного ИИ, что позволяет создавать более естественные и эффективные взаимодействия в приложениях обслуживания клиентов и виртуальных ассистентов.
Помимо поиска и чат-ботов, архитектура BERT была адаптирована для задач, таких как анализ настроений, классификация документов и ответы на вопросы. Его способность к дообучению для конкретных задач с использованием относительно небольших наборов данных демократизировала доступ к передовым NLP технологиям, позволяя организациям любого размера внедрять продвинутые возможности понимания языков. В результате BERT продолжает стимулировать инновации в различных отраслях, от здравоохранения до финансов, позволяя машинам обрабатывать и интерпретировать человеческий язык с беспрецедентной точностью и нюансами.
Ограничения и вызовы: Где BERT не справляется
Несмотря на его трансформационное влияние на обработку естественного языка, у BERT есть несколько заметных ограничений и вызовов. Одним из основных беспокойств является его вычислительная интенсивность; как предварительное обучение, так и адаптация BERT требуют значительных аппаратных ресурсов, что делает его менее доступным для организаций с ограниченной вычислительной инфраструктурой. Большой размер модели также приводит к высокому потреблению памяти и более медленному времени вывода, что может помешать развертыванию в режиме реального времени или в ресурсозависимых средах (Google AI Blog).
Архитектура BERT по своей природе ограничена фиксированной длиной входных последовательностей, обычно не превышающей 512 токенов. Это ограничение создает проблемы для задач, связанных с более длинными документами, поскольку требуется усечение или сложные стратегии разбиения, что может привести к потере контекста и снижению производительности (arXiv). Более того, BERT предварительно обучается на крупных корпусах общего назначения, что может привести к субоптимальной производительности на специфичных для домена задачах, если не проведена дальнейшая адаптация к домену.
Еще одним вызовом является неспособность BERT выполнять рассуждения или обрабатывать задачи, требующие знания об окружающем мире, выходящего за пределы его обучающей информации. Модель также уязвима для атак и может генерировать предвзятые или бессмысленные результаты, отражая предвзятости, присутствующие в ее обучающих данных (Национальный институт стандартов и технологий (NIST)). Более того, интерпретируемость BERT остается ограниченной, что затрудняет понимание или объяснение его предсказаний, что является серьезной проблемой для приложений в чувствительных областях, таких как здравоохранение или право.
Будущее BERT: Инновации, варианты и что дальше
С момента своего появления двунаправленные кодировочные представления от трансформеров (BERT) произвели революцию в обработке естественного языка (NLP), но поле продолжает быстро развиваться. Будущее BERT формируется продолжающимися инновациями, появлением множества вариантов и интеграцией новых техник для решения его ограничений. Одним из основных направлений является развитие более эффективных и масштабируемых моделей. Например, модели, такие как DistilBERT и TinyBERT, предлагают легковесные альтернативы, которые сохраняют большую часть производительности BERT, снижая при этом вычислительные требования, что делает их подходящими для развертывания на краевых устройствах и в приложениях в реальном времени (Hugging Face).
Другим значительным направлением является адаптация BERT для многоязычных и специфичных для домена задач. Многоязычный BERT (mBERT) и такие модели, как BioBERT и SciBERT, создаются для конкретных языков или научных областей, демонстрируя гибкость архитектуры BERT (Google AI Blog). Дополнительно исследования сосредоточены на улучшении интерпретируемости и устойчивости BERT, решая проблемы прозрачности модели и уязвимости к атакам.
Смотрев в будущее, интеграция BERT с другими модальностями, такими как зрение и речь, представляет собой многообещающую область, как было показано в моделях, таких как VisualBERT и SpeechBERT. Более того, рост крупных предобученных моделей, таких как GPT-3 и T5, вдохновил на создание гибридных архитектур, которые сочетают в себе преимущества двунаправленного кодирования BERT с генеративными возможностями (Google AI Blog). Поскольку исследования продолжаются, ожидается, что BERT и его преемники будут играть центральную роль в расширении возможностей систем ИИ в различных приложениях.
Источник и ссылки
- Google AI Language
- Vaswani и др. (2017)
- Google Research
- Национальный институт стандартов и технологий (NIST)
- Hugging Face