Wnętrze BERT: Jak dwukierunkowe reprezentacje encodera z transformatorów redefiniują przetwarzanie języka naturalnego i napędzają nową generację aplikacji AI
- Wprowadzenie do BERT: Pochodzenie i przełomy
- Jak działa BERT: Nauka za dwukierunkowymi transformatorami
- Pre-trening i dostrajanie: Dwuetapowy proces uczenia się BERT-a
- BERT vs. tradycyjne modele NLP: Co go wyróżnia?
- Praktyczne zastosowania: BERT w wyszukiwarkach, chatbotach i nie tylko
- Ograniczenia i wyzwania: Gdzie BERT ma braki
- Przyszłość BERT: Innowacje, warianty i co dalej
- Źródła i odniesienia
Wprowadzenie do BERT: Pochodzenie i przełomy
Dwukierunkowe reprezentacje encodera z transformatorów (BERT) stanowią znaczący kamień milowy w ewolucji przetwarzania języka naturalnego (NLP). Wprowadzone przez badaczy z Google AI Language w 2018 roku, BERT fundamentalnie zmienił sposób, w jaki maszyny rozumieją język, wykorzystując moc głębokich dwukierunkowych transformatorów. W przeciwieństwie do wcześniejszych modeli, które przetwarzały tekst od lewej do prawej lub od prawej do lewej, architektura BERT-a pozwala mu uwzględniać pełen kontekst słowa, patrząc jednocześnie na jego lewe i prawe otoczenie. To podejście dwukierunkowe umożliwia bardziej zniuansowane zrozumienie języka, uchwycając subtelne relacje i znaczenia, które często umykają modelom jednokierunkowym.
Pochodzenie BERT-a opiera się na architekturze transformatora, po raz pierwszy wprowadzonej przez Vaswani et al. (2017), która polega na mechanizmach samo-uwagi do przetwarzania sekwencji wejściowych równolegle. Poprzez pre-trening na ogromnych zbiorach danych, takich jak Wikipedia i BooksCorpus, BERT uczy się ogólnych reprezentacji językowych, które można dostosować do szerokiego wachlarza zadań downstream, w tym odpowiedzi na pytania, analizy sentymentu i rozpoznawania bytów nazwanych. Wydanie BERT-a ustaliło nowe standardy w wielu zadaniach NLP, przewyższając wcześniejsze modele uznawane za stan wiedzy i inspirując falę badań nad architekturami opartymi na transformatorach.
Przełomy osiągnięte dzięki BERT-owi nie tylko posunęły naprzód badania akademickie, ale także przyniosły praktyczne ulepszenia w aplikacjach komercyjnych, takich jak wyszukiwarki i wirtualni asystenci. Jego otwarto-źródłowe wydanie zdemokratyzowało dostęp do potężnych modeli językowych, sprzyjając innowacjom i współpracy w całej społeczności NLP.
Jak działa BERT: Nauka za dwukierunkowymi transformatorami
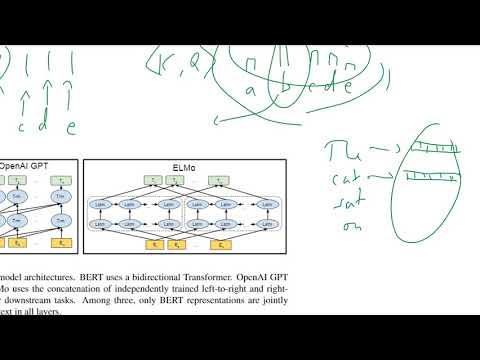
Główna innowacja BERT-a polega na zastosowaniu dwukierunkowych transformatorów, które zasadniczo zmieniają sposób, w jaki modele językowe rozumieją kontekst. W przeciwieństwie do tradycyjnych modeli, które przetwarzają tekst od lewej do prawej lub od prawej do lewej, BERT wykorzystuje architekturę transformatora do jednoczesnej analizy wszystkich słów w zdaniu, uwzględniając zarówno słowa poprzedzające, jak i następujące. To podejście dwukierunkowe pozwala BERT-owi uchwycić zniuansowane relacje i zależności w języku, prowadząc do głębszego zrozumienia znaczenia i kontekstu.
Nauka za dwukierunkowością BERT-a opiera się na jego zadaniach pre-treningowych: Maskowane modelowanie językowe (MLM) i predykcja następnego zdania (NSP). W MLM losowe słowa w zdaniu są maskowane, a model uczy się przewidywać te zamaskowane tokeny, biorąc pod uwagę cały kontekst po obu stronach. W przeciwieństwie do wcześniejszych modeli, które mogły korzystać tylko z częściowego kontekstu, co ograniczało ich zrozumienie. NSP z kolei uczy BERT-a rozumienia relacji pomiędzy parami zdań, co dalej zwiększa jego zrozumienie kontekstu i spójności.
Architektura BERT-a opiera się na encodera transformatora, który wykorzystuje mechanizmy samo-uwagi do oceny znaczenia każdego słowa w odniesieniu do innych w wejściu. Umożliwia to BERT-owi modelowanie złożonych zjawisk lingwistycznych, takich jak polisemiczność i zależności długozasięgowe. Efektem jest model, który osiąga stan wiedzy w szerokim zakresie zadań przetwarzania języka naturalnego, w tym odpowiedzi na pytania i analizy sentymentu. Aby uzyskać szczegółowy przegląd techniczny, odwołaj się do oryginalnego dokumentu autorstwa Google AI Language i oficjalnej dokumentacji od Google Research.
Pre-trening i dostrajanie: Dwuetapowy proces uczenia się BERT-a
Niezwykłe osiągi BERT-a w zadaniach przetwarzania języka naturalnego są w dużej mierze przypisywane jego innowacyjnemu procesowi uczenia się w dwóch etapach: pre-trening i dostrajanie. Podczas fazy pre-treningu BERT jest narażony na ogromne ilości nienazwanego tekstu, ucząc się ogólnych reprezentacji językowych poprzez dwa zadania samo-nadzorowane: Maskowane modelowanie językowe (MLM) i predykcja następnego zdania (NSP). W MLM losowe słowa w zdaniu są maskowane, a model uczy się przewidywać te zamaskowane tokeny na podstawie ich kontekstu, co umożliwia głębokie dwukierunkowe zrozumienie. NSP z kolei uczy BERT-a, aby określić, czy jedno zdanie logicznie wynika z drugiego, co jest kluczowe w zadaniach związanych z relacjami między zdaniami (Google Research).
Po pre-treningu BERT przechodzi przez dostrajanie na konkretnych zadaniach downstream, takich jak odpowiedzi na pytania, analiza sentymentu czy rozpoznawanie bytów nazwanych. W tym etapie pre-trenowany model jest dalej trenowany na mniejszym, oznaczonym zbiorze danych dopasowanym do docelowego zadania. Architektura pozostaje w dużej mierze niezmieniona, ale w razie potrzeby dodawane są warstwy specyficzne dla zadania (np. głowice klasyfikacyjne). Dostosowywanie zazwyczaj wymaga tylko kilku epok i stosunkowo niewielu danych, ponieważ model już nabył solidne zrozumienie języka w trakcie pre-treningu. To podejście w dwóch etapach pozwala BERT-owi osiągnąć wyniki na poziomie stanu wiedzy w szerokim zakresie standardów NLP, demonstrując skuteczność transferu uczenia się w modelach językowych (Google AI Blog).
BERT vs. tradycyjne modele NLP: Co go wyróżnia?
BERT (Dwukierunkowe reprezentacje encodera z transformatorów) stanowi znaczącą zmianę w porównaniu do tradycyjnych modeli przetwarzania języka naturalnego (NLP), przede wszystkim dzięki swojemu dwukierunkowemu rozumieniu kontekstu i architekturze opartej na transformatorach. Tradycyjne modele NLP, takie jak modele worków słów, modele n-gramowe i wcześniejsze embeddingi słów, takie jak Word2Vec czy GloVe, zazwyczaj przetwarzają tekst w sposób jednokierunkowy lub niezależny od kontekstu. Na przykład modele takie jak Word2Vec generują wektory słów na podstawie lokalnych okien kontekstowych, a sieci neuronowe rekurencyjne (RNN) przetwarzają sekwencje od lewej do prawej lub od prawej do lewej, ograniczając ich zdolność do uchwycenia pełnego kontekstu zdania.
W przeciwieństwie do tego, BERT wykorzystuje architekturę transformatora, która umożliwia mu jednoczesne uwzględnianie kontekstu po lewej i prawej stronie dla każdego słowa w zdaniu. To dwukierunkowe podejście pozwala BERT-owi generować bogatsze, wrażliwe na kontekst reprezentacje słów, co jest szczególnie korzystne dla zadań wymagających zniuansowanego zrozumienia, takich jak odpowiedzi na pytania i analiza sentymentu. Ponadto BERT jest wstępnie trenowany na dużych zbiorach danych z wykorzystaniem celów w zakresie maskowanego modelowania językowego i predykcji następnego zdania, co pozwala mu nauczyć się głębokich cech semantycznych i syntaktycznych przed dostosowaniem do konkretnych zadań downstream.
Wyniki empiryczne pokazują, że BERT konsekwentnie przewyższa tradycyjne modele w szerokim zakresie punktów odniesienia NLP, w tym w zbiorach danych GLUE i SQuAD. Jego architektura i paradygmat treningowy ustawiły nowe standardy transferu uczenia się w NLP, umożliwiając praktykom osiąganie wyników na poziomie stanu wiedzy z minimalnymi modyfikacjami architektury specyficznej dla zadania. Po więcej szczegółów odwołaj się do oryginalnego dokumentu autorstwa Google AI Language oraz oficjalnego repozytorium BERT na GitHubie.
Praktyczne zastosowania: BERT w wyszukiwarkach, chatbotach i nie tylko
Transformujący wpływ BERT-a na przetwarzanie języka naturalnego (NLP) jest najbardziej widoczny w jego praktycznych zastosowaniach, szczególnie w wyszukiwarkach, chatbotach i różnych innych dziedzinach. W wyszukiwarce BERT umożliwia systemom lepsze zrozumienie kontekstu i intencji stojącej za zapytaniami użytkowników, prowadząc do bardziej odpowiednich i dokładnych wyników. Na przykład, Google zintegrował BERT-a z swoimi algorytmami wyszukiwania, aby poprawić interpretację zapytań konwersacyjnych, zwłaszcza tych dotyczących przyimków i złożonych sformułowań. Ten postęp pozwala wyszukiwarkom dobierać zapytania z treścią w sposób, który bardziej przypomina ludzkie zrozumienie.
W dziedzinie konwersacyjnej sztucznej inteligencji BERT znacznie poprawił wydajność chatbotów. Wykorzystując swoje głębokie dwukierunkowe zrozumienie kontekstu, chatboty mogą generować bardziej spójne i odpowiednie kontekstowo odpowiedzi, co poprawia zadowolenie i zaangażowanie użytkowników. Firmy takie jak Microsoft wprowadziły BERT-a do swoich platform AI konwersacyjnej, umożliwiając bardziej naturalne i efektywne interakcje w obsłudze klienta i aplikacjach wirtualnych asystentów.
Poza wyszukiwarkami i chatbotami, architektura BERT-a została zaadoptowana do zadań takich jak analiza sentymentu, klasyfikacja dokumentów i odpowiadanie na pytania. Jego zdolność do dostosowania się do specyficznych zadań przy stosunkowo małych zbiorach danych zdemokratyzowała dostęp do zaawansowanego NLP, pozwalając organizacjom różnej wielkości wdrażać zaawansowane zdolności rozumienia języka. W rezultacie BERT nadal napędza innowacje w różnych branżach, od ochrony zdrowia po finanse, umożliwiając maszynom przetwarzanie i interpretację ludzkiego języka z niespotykaną wcześniej dokładnością i złożonością.
Ograniczenia i wyzwania: Gdzie BERT ma braki
Pomimo swojego transformacyjnego wpływu na przetwarzanie języka naturalnego, BERT wykazuje kilka zauważalnych ograniczeń i wyzwań. Jednym z głównych problemów jest jego intensywność obliczeniowa; zarówno pre-trening, jak i dostrajanie BERT-a wymagają znacznych zasobów sprzętowych, co sprawia, że jest on mniej dostępny dla organizacji z ograniczoną infrastrukturą obliczeniową. Duża wielkość modelu prowadzi również do wysokiego zużycia pamięci i wolniejszych czasów wnioskowania, co może utrudniać wdrażanie w środowiskach rzeczywistych lub ograniczonych zasobach (Google AI Blog).
Architektura BERT-a jest z natury ograniczona do sekwencji wejściowych o stałej długości, które zwykle są ograniczone do 512 tokenów. To ograniczenie stwarza wyzwania dla zadań związanych z dłuższymi dokumentami, ponieważ wymagane są strategie skrócenia lub złożone dzielenie, co może prowadzić do utraty kontekstu i pogorszenia wydajności (arXiv). Ponadto BERT jest wstępnie trenowany na dużych, ogólnych zbiorach danych, co może prowadzić do suboptymalnych wyników w zadaniach specyficznych dla danej dziedziny, chyba że dokonano dalszej adaptacji dziedzinowej.
Innym wyzwaniem jest niemożność BERT-a wykonywania rozumowania lub obsługiwania zadań wymagających wiedzy o świecie poza tym, co znajduje się w jego danych treningowych. Model jest również podatny na ataki adwersarialne i może produkować stronnicze lub bezsensowne wyniki, odzwierciedlające uprzedzenia obecne w jego danych treningowych (National Institute of Standards and Technology (NIST)). Co więcej, interpretacja BERT-a pozostaje ograniczona, co utrudnia zrozumienie lub wyjaśnienie jego prognoz, co jest znaczącym problemem w zastosowaniach w wrażliwych dziedzinach, takich jak opieka zdrowotna czy prawo.
Przyszłość BERT: Innowacje, warianty i co dalej
Od momentu swojego wprowadzenia, dwukierunkowe reprezentacje encodera z transformatorów (BERT) zrewolucjonizowały przetwarzanie języka naturalnego (NLP), ale dziedzina ta wciąż szybko się rozwija. Przyszłość BERT-a kształtowana jest przez bieżące innowacje, powstawanie licznych wariantów oraz integrację nowych technik mających na celu rozwiązanie jego ograniczeń. Jednym z głównych kierunków jest opracowywanie bardziej efektywnych i skalowalnych modeli. Na przykład, modele takie jak DistilBERT i TinyBERT oferują lekkie alternatywy, które zachowują dużą część wydajności BERT-a, przy jednoczesnym redukowaniu wymagań obliczeniowych, co czyni je odpowiednimi do wdrażania na urządzeniach brzegowych i w aplikacjach rzeczywistych (Hugging Face).
Innym znaczącym trendem jest dostosowanie BERT-a do zadań wielojęzycznych i specyficznych dla danych dziedzin. Wielojęzyczny BERT (mBERT) oraz modele takie jak BioBERT i SciBERT są dostosowane do konkretnych języków lub dziedzin naukowych, co pokazuje elastyczność architektury BERT (Google AI Blog). Dodatkowo, badania koncentrują się na poprawie interpretowalności BERT-a i jego odporności, co odpowiada na obawy dotyczące przejrzystości modelu i podatności na ataki adwersarialne.
Patrząc w przyszłość, integracja BERT-a z innymi modalnościami, takimi jak wizja i mowa, jest obiecującym obszarem, co widać w modelach takich jak VisualBERT i SpeechBERT. Co więcej, rozwój modeli wstępnie wytrenowanych na dużą skalę, takich jak GPT-3 i T5, zainspirował hybrydowe architektury, które łączą moc dwukierunkowego kodowania BERT-a z możliwościami generatywnymi (Google AI Blog). W miarę postępu badań oczekuje się, że BERT i jego następcy odgrywać będą kluczową rolę w podnoszeniu możliwości systemów AI w różnorodnych zastosowaniach.
Źródła i odniesienia
- Google AI Language
- Vaswani et al. (2017)
- Google Research
- National Institute of Standards and Technology (NIST)
- Hugging Face