Binnen BERT: Hoe Bidirectionele Encoder Representaties van Transformers de Natuurlijke Taalverwerking Herdefiniëren en de Volgende Generatie AI-toepassingen Aandrijven
- Inleiding tot BERT: Oorsprong en Doorbraken
- Hoe BERT Werkt: De Wetenschap Achter Bidirectionele Transformers
- Voortraining en Fijnstelling: BERT’s Twee-Fasen Leerproces
- BERT vs. Traditionele NLP Modellen: Wat Maakt Het Anders?
- Toepassingen in de Praktijk: BERT in Zoekmachines, Chatbots en Meer
- Beperkingen en Uitdagingen: Waar BERT Tekortschiet
- De Toekomst van BERT: Innovaties, Varianten, en Wat Volgt
- Bronnen & Referenties
Inleiding tot BERT: Oorsprong en Doorbraken
Bidirectionele Encoder Representaties van Transformers (BERT) vertegenwoordigen een belangrijke mijlpaal in de evolutie van de natuurlijke taalverwerking (NLP). Geïntroduceerd door onderzoekers van Google AI Language in 2018, veranderde BERT fundamenteel de manier waarop machines taal begrijpen door gebruik te maken van de kracht van diepe bidirectionele transformers. In tegenstelling tot eerdere modellen die tekst ofwel van links naar rechts of van rechts naar links verwerkten, stelt de architectuur van BERT het in staat om de volledige context van een woord in overweging te nemen door zowel de linker als rechter omgeving tegelijkertijd te bekijken. Deze bidirectionele aanpak maakt een nuanceuzer begrip van taal mogelijk, waardoor subtiele relaties en betekenissen worden vastgelegd die unidirectionele modellen vaak missen.
De oorsprong van BERT is geworteld in de transformer-architectuur, die voor het eerst werd geïntroduceerd door Vaswani et al. (2017), die afhankelijk is van zelf-attentiemechanismen om invoersequenties parallel te verwerken. Door te pre-trainen op enorme corpus zoals Wikipedia en BooksCorpus, leert BERT algemene taalrepresentaties die kunnen worden fijngesteld voor een breed scala aan downstream-taken, waaronder vraagbeantwoording, sentimentanalyse en naamherkenning. De release van BERT heeft nieuwe benchmarks gezet in verschillende NLP-taken, met een betere prestatie dan eerdere state-of-the-art modellen en inspiratie gegeven voor een golf van onderzoek naar transformer-gebaseerde architecturen.
De doorbraken die door BERT zijn bereikt, hebben niet alleen de academische onderzoek bevorderd, maar ook geleid tot praktische verbeteringen in commerciële toepassingen, zoals zoekmachines en virtuele assistenten. De open-source release heeft de toegang tot krachtige taalkundige modellen gedemocratiseerd, waardoor innovatie en samenwerking binnen de NLP-gemeenschap gestimuleerd worden.
Hoe BERT Werkt: De Wetenschap Achter Bidirectionele Transformers
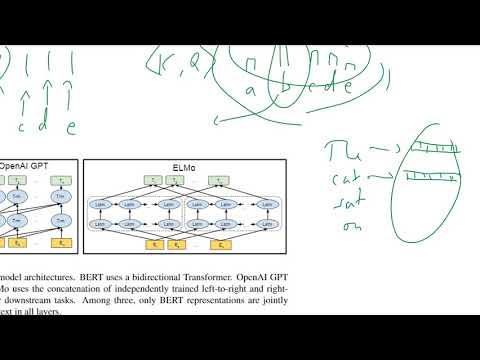
De kerninnovatie van BERT ligt in het gebruik van bidirectionele transformers, die fundamenteel veranderen hoe taalmodellen context begrijpen. In tegenstelling tot traditionele modellen die tekst van links naar rechts of van rechts naar links verwerken, benut BERT een transformer-architectuur om alle woorden in een zin tegelijkertijd te analyseren, met inachtneming van zowel voorafgaande als opvolgende woorden. Deze bidirectionele aanpak stelt BERT in staat om genuanceerde relaties en afhankelijkheden binnen de taal vast te leggen, wat leidt tot een dieper begrip van betekenis en context.
De wetenschap achter de bidirectionaliteit van BERT is geworteld in zijn voortraingstaken: Gemaskerde Taalmodellering (MLM) en Volgende Zinsvoorspelling (NSP). In MLM worden willekeurige woorden in een zin gemaskeerd, en leert het model deze gemaskeerde tokens te voorspellen door de gehele context aan beide zijden in overweging te nemen. Dit staat in contrast met eerdere modellen, die alleen een gedeeltelijke context konden gebruiken, wat hun begrip beperkte. NSP daarentegen, traint BERT om de relatie tussen zinnenparen te begrijpen, wat zijn begrip van context en coherentie verder verbetert.
De architectuur van BERT is gebaseerd op de transformer-encoder, die zelf-attentiemechanismen gebruikt om het belang van elk woord ten opzichte van andere woorden in de invoer te wegen. Dit stelt BERT in staat complexe linguïstische verschijnselen zoals polysemie en lange-afstandsafhankelijkheden te modelleren. Het resultaat is een model dat state-of-the-art prestaties behaalt op een breed scala van NLP-taken, waaronder vraagbeantwoording en sentimentanalyse. Voor een gedetailleerd technisch overzicht, verwijzen we naar het oorspronkelijke artikel van Google AI Language en de officiële documentatie van Google Research.
Voortraining en Fijnstelling: BERT’s Twee-Fasen Leerproces
De opmerkelijke prestaties van BERT in taken van natuurlijke taalverwerking zijn grotendeels toe te schrijven aan zijn innovatieve twee-fasen leerproces: voortraining en fijnstelling. Tijdens de voortraining fase wordt BERT blootgesteld aan enorme hoeveelheden ongelabelde tekst, waarbij het algemene taalrepresentaties leert door middel van twee zelf-geassisteerde taken: Gemaskerde Taalmodellering (MLM) en Volgende Zinsvoorspelling (NSP). In MLM worden willekeurige woorden in een zin gemaskeerd, en leert het model deze gemaskeerde tokens te voorspellen op basis van hun context, wat een diep bidirectioneel begrip mogelijk maakt. NSP traint BERT daarentegen om te bepalen of de ene zin logisch de andere volgt, wat cruciaal is voor taken die zinnenrelaties vereisen (Google Research).
Na de voortraining ondergaat BERT fijnstelling op specifieke downstream-taken zoals vraagbeantwoording, sentimentanalyse of naamherkenning. In deze fase wordt het voorgetrainde model verder getraind op een kleinere, gelabelde dataset die is afgestemd op de doeltaak. De architectuur blijft grotendeels ongewijzigd, maar taak-specifieke lagen (bijvoorbeeld classificatie-headers) worden toegevoegd indien nodig. Fijnstelling vereist doorgaans slechts enkele epochs en relatief weinig data, aangezien het model tijdens de voortraining al een robuust begrip van taal heeft verworven. Deze twee-fasen aanpak stelt BERT in staat om state-of-the-art resultaten te behalen in een breed scala aan NLP-benchmarks, wat de effectiviteit van transfer learning in taalmodellen aantoont (Google AI Blog).
BERT vs. Traditionele NLP Modellen: Wat Maakt Het Anders?
BERT (Bidirectionele Encoder Representaties van Transformers) vertegenwoordigt een significante afwijking van traditionele natuurlijke taalverwerkingsmodellen, voornamelijk vanwege zijn bidirectionele contextbegrip en transformer-gebaseerde architectuur. Traditionele NLP-modellen, zoals bag-of-words, n-gram-modellen en eerdere woordembeddingstechnieken zoals Word2Vec of GloVe, verwerken tekst meestal op een unidirectionele of context-onafhankelijke manier. Bijvoorbeeld, modellen zoals Word2Vec genereren woordvectoren die uitsluitend zijn gebaseerd op lokale contextvensters, en recurrente neurale netwerken (RNN’s) verwerken sequenties van links naar rechts of van rechts naar links, waardoor hun vermogen om de volledige zincontext vast te leggen beperkt is.
In tegenstelling hiermee benut BERT een transformer-architectuur die het mogelijk maakt om zowel de linker als rechter context tegelijkertijd voor elk woord in een zin te overwegen. Deze bidirectionele aanpak stelt BERT in staat rijkere, contextgevoelige representaties van woorden te genereren, wat bijzonder voordelig is voor taken die een genuanceerd begrip vereisen, zoals vraagbeantwoording en sentimentanalyse. Bovendien is BERT voorgetraind op grote corpus met behulp van gemaskerde taalmodellering en doelen voor volgende zinsvoorspelling, waardoor het in staat is om diepe semantische en syntactische kenmerken te leren voordat het wordt fijngesteld op specifieke downstream-taken.
Empirische resultaten hebben aangetoond dat BERT consequent betere prestaties levert dan traditionele modellen in een breed scala aan NLP-benchmarks, waaronder de GLUE- en SQuAD-datasets. De architectuur en trainingsparadigma hebben nieuwe normen gesteld voor transfer learning in NLP, waardoor practitioners state-of-the-art resultaten kunnen behalen met minimale taak-specifieke architectuurwijzigingen. Voor meer details, zie het originele artikel van Google AI Language en de officiële BERT GitHub-repository.
Toepassingen in de Praktijk: BERT in Zoekmachines, Chatbots en Meer
BERT’s transformerende impact op natuurlijke taalverwerking (NLP) is het duidelijkst zichtbaar in zijn toepassingen in de praktijk, vooral in zoekmachines, chatbots en diverse andere domeinen. In zoekmachines stelt BERT systemen in staat om de context en intentie achter gebruikersvragen beter te begrijpen, wat leidt tot relevantere en nauwkeurigere resultaten. Zo heeft Google BERT geïntegreerd in zijn zoekalgoritmen om de interpretatie van gesprekstarigen, vooral die met voorzetsels en nuancevolle formuleringen, te verbeteren. Deze vooruitgang stelt zoekmachines in staat om vragen met inhoud af te stemmen op een manier die meer lijkt op menselijk begrip.
Op het gebied van conversatie-AI heeft BERT de prestaties van chatbots aanzienlijk verbeterd. Door gebruik te maken van zijn diepe bidirectionele context, kunnen chatbots coherenter en contextueel passende antwoorden genereren, wat de gebruikerservaring en betrokkenheid verbetert. Bedrijven zoals Microsoft hebben BERT geïntegreerd in hun conversational AI-platforms, waardoor natuurlijkere en effectievere interacties in klantservice en virtuele assistenttoepassingen mogelijk zijn.
Buiten zoekmachines en chatbots is de architectuur van BERT aangepast voor taken zoals sentimentanalyse, documentclassificatie en vraagbeantwoording. Het vermogen om te worden fijngestemd voor specifieke taken met relatief kleine datasets heeft de toegang tot state-of-the-art NLP gedemocratiseerd, waardoor organisaties van elke omvang geavanceerde taalkundige mogelijkheden kunnen implementeren. Als gevolg daarvan blijft BERT innovatie in verschillende industrieën aandrijven, van gezondheidszorg tot financiën, door machines in staat te stellen menselijke taal met ongekende nauwkeurigheid en nuance te verwerken en te interpreteren.
Beperkingen en Uitdagingen: Waar BERT Tekortschiet
Ondanks zijn transformerende impact op natuurlijke taalverwerking vertoont BERT verschillende opvallende beperkingen en uitdagingen. Een belangrijke zorg is de rekenintensiteit; zowel de voortraining als de fijnstelling van BERT vereisen aanzienlijke hardwarebronnen, waardoor het minder toegankelijk is voor organisaties met beperkte rekeninfrastructuur. De grote omvang van het model leidt ook tot een hoog geheugengebruik en tragere inferentietijden, wat de implementatie in realtime of resource-beperkte omgevingen kan belemmeren (Google AI Blog).
De architectuur van BERT is inherent beperkt tot invoersequenties met een vaste lengte, meestal beperkt tot 512 tokens. Deze beperking vormt uitdagingen voor taken die langere documenten omvatten, aangezien truncatie of complexe splitsstrategieën vereist zijn, wat kan leiden tot verlies van context en verminderde prestaties (arXiv). Bovendien is BERT voorgetraind op grote, generieke corpus, wat kan leiden tot suboptimale prestaties op domeinspecifieke taken, tenzij verdere domeinadaptatie wordt uitgevoerd.
Een andere uitdaging is BERT’s onvermogen om redeneringen uit te voeren of taken aan te pakken die wereldkennis vereisen die verder gaat dan wat in zijn trainingsdata aanwezig is. Het model is ook gevoelig voor aanvallen en kan bevooroordeelde of onzinnige outputs produceren, wat de vooroordelen in zijn trainingsdata weerspiegelt (National Institute of Standards and Technology (NIST)). Bovendien blijft de interpreteerbaarheid van BERT beperkt, waardoor het moeilijk is om zijn voorspellingen te begrijpen of uit te leggen, wat een aanzienlijke zorg is voor toepassingen in gevoelige domeinen zoals gezondheidszorg of recht.
De Toekomst van BERT: Innovaties, Varianten, en Wat Volgt
Sinds zijn introductie heeft Bidirectionele Encoder Representaties van Transformers (BERT) de natuurlijke taalverwerking (NLP) revolutionair veranderd, maar het veld blijft zich snel ontwikkelen. De toekomst van BERT wordt gevormd door voortdurende innovaties, de opkomst van talrijke varianten en de integratie van nieuwe technieken om zijn beperkingen aan te pakken. Een belangrijke richting is de ontwikkeling van efficiëntere en schaalbare modellen. Bijvoorbeeld modellen zoals DistilBERT en TinyBERT bieden lichte alternatieven die veel van BERT’s prestaties behouden terwijl ze de rekenvereisten verlagen, waardoor ze geschikt zijn voor implementatie op edge-apparaten en in realtime toepassingen (Hugging Face).
Een andere belangrijke trend is de aanpassing van BERT voor meertalige en domein-specifieke taken. Meertalig BERT (mBERT) en modellen zoals BioBERT en SciBERT zijn aangepast voor specifieke talen of wetenschappelijke domeinen, wat de flexibiliteit van de BERT-architectuur aantoont (Google AI Blog). Bovendien is het onderzoek gericht op het verbeteren van BERT’s interpreteerbaarheid en robuustheid, waarbij zorgen over modeltransparantie en kwetsbaarheden voor aanvallen worden aangepakt.
Als we vooruitkijken, is de integratie van BERT met andere modaliteiten, zoals visie en spraak, een veelbelovende richting, zoals te zien is in modellen zoals VisualBERT en SpeechBERT. Verder heeft de opkomst van grootschalige voorgetrainde modellen, zoals GPT-3 en T5, hybride architecturen geïnspireerd die de sterke punten van BERT’s bidirectionele codering combineren met generatieve mogelijkheden (Google AI Blog). Naarmate het onderzoek doorgaat, wordt verwacht dat BERT en zijn opvolgers een centrale rol zullen spelen in het verbeteren van de mogelijkheden van AI-systemen in diverse toepassingen.
Bronnen & Referenties
- Google AI Language
- Vaswani et al. (2017)
- Google Research
- National Institute of Standards and Technology (NIST)
- Hugging Face