Dentro BERT: Come le Rappresentazioni degli Encoder Bidirezionali dei Trasformatori Stanno Ridefinendo l’elaborazione del Linguaggio Naturale e Alimentando la Prossima Generazione di Applicazioni AI
- Introduzione a BERT: Origini e Innovazioni
- Come Funziona BERT: La Scienza Dietro i Trasformatori Bidirezionali
- Pre-allenamento e Ottimizzazione: Il Processo di Apprendimento a Due Fasi di BERT
- BERT vs. Modelli NLP Tradizionali: Cosa lo Differenzia?
- Applicazioni nel Mondo Reale: BERT nella Ricerca, nei Chatbot e Oltre
- Limitazioni e Sfide: In Cosa BERT È Carente
- Il Futuro di BERT: Innovazioni, Varianti e Cosa Aspettarsi
- Fonti & Riferimenti
Introduzione a BERT: Origini e Innovazioni
Le Rappresentazioni degli Encoder Bidirezionali dei Trasformatori (BERT) rappresentano una pietra miliare significativa nell’evoluzione dell’elaborazione del linguaggio naturale (NLP). Introdotto da ricercatori di Google AI Language nel 2018, BERT ha cambiato radicalmente il modo in cui le macchine comprendono il linguaggio sfruttando la potenza dei trasformatori bidirezionali profondi. A differenza dei modelli precedenti che elaboravano il testo da sinistra a destra o da destra a sinistra, l’architettura di BERT consente di considerare il contesto completo di una parola esaminando sia l’ambiente a sinistra sia quello a destra contemporaneamente. Questo approccio bidirezionale consente una comprensione più sfumata del linguaggio, catturando relazioni e significati sottili che i modelli unidirezionali spesso trascurano.
Le origini di BERT si radicano nell’architettura dei trasformatori, introdotta per la prima volta da Vaswani et al. (2017), che si basa su meccanismi di autoattenzione per elaborare le sequenze di input in parallelo. Attraverso il pre-allenamento su enormi corpora come Wikipedia e BooksCorpus, BERT apprende rappresentazioni generali del linguaggio che possono essere ottimizzate per una vasta gamma di compiti secondari, tra cui risposte a domande, analisi del sentiment e riconoscimento di entità nominate. Il rilascio di BERT ha stabilito nuovi standard in diverse attività di NLP, superando i modelli all’avanguardia precedenti e ispirando un’ondata di ricerca sulle architetture basate sui trasformatori.
Le innovazioni raggiunte da BERT non solo hanno avanzato la ricerca accademica, ma hanno anche portato a miglioramenti pratici nelle applicazioni commerciali, come i motori di ricerca e gli assistenti virtuali. Il suo rilascio open-source ha democratizzato l’accesso a modelli linguistici potenti, promuovendo innovazione e collaborazione all’interno della comunità NLP.
Come Funziona BERT: La Scienza Dietro i Trasformatori Bidirezionali
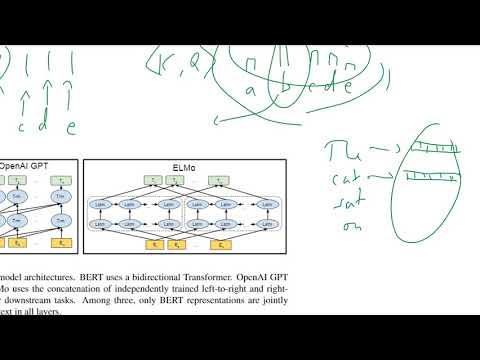
L’innovazione principale di BERT risiede nell’uso dei trasformatori bidirezionali, che cambiano fondamentalmente il modo in cui i modelli linguistici comprendono il contesto. A differenza dei modelli tradizionali che elaborano il testo da sinistra a destra o da destra a sinistra, BERT sfrutta un’architettura di trasformatori per analizzare tutte le parole in una frase simultaneamente, considerando sia le parole precedenti che quelle successive. Questo approccio bidirezionale consente a BERT di catturare relazioni e dipendenze sfumate all’interno del linguaggio, portando a una comprensione più profonda del significato e del contesto.
La scienza dietro la bidirezionalità di BERT si basa sui suoi compiti di pre-allenamento: Modello di Linguaggio Mascherato (MLM) e Predizione della Prossima Frase (NSP). Nell’MLM, parole casuali in una frase vengono mascherate, e il modello impara a prevedere questi token mascherati considerando l’intero contesto su entrambi i lati. Questo contrasta con i modelli precedenti, che potevano utilizzare solo un contesto parziale, limitando la loro comprensione. NSP, d’altro canto, allena BERT a comprendere la relazione tra coppie di frasi, migliorando ulteriormente la sua comprensione del contesto e della coerenza.
L’architettura di BERT si basa sull’encoder di trasformatori, che utilizza meccanismi di autoattenzione per pesare l’importanza di ogni parola rispetto alle altre nell’input. Questo consente a BERT di modellare fenomeni linguistici complessi come la polisemia e le dipendenze a lungo raggio. Il risultato è un modello che raggiunge prestazioni all’avanguardia in un’ampia gamma di compiti di elaborazione del linguaggio naturale, tra cui risposte a domande e analisi del sentiment. Per una panoramica tecnica dettagliata, fare riferimento al documento originale di Google AI Language e alla documentazione ufficiale di Google Research.
Pre-allenamento e Ottimizzazione: Il Processo di Apprendimento a Due Fasi di BERT
Le straordinarie prestazioni di BERT nei compiti di elaborazione del linguaggio naturale sono in gran parte attribuibili al suo innovativo processo di apprendimento a due fasi: pre-allenamento e ottimizzazione. Durante la fase di pre-allenamento, BERT viene esposto a enormi quantità di testo non etichettato, apprendendo rappresentazioni generali del linguaggio attraverso due compiti di auto-supervisione: Modello di Linguaggio Mascherato (MLM) e Predizione della Prossima Frase (NSP). Nell’MLM, parole casuali in una frase vengono mascherate, e il modello apprende a prevedere questi token mascherati in base al loro contesto, consentendo una profonda comprensione bidirezionale. NSP, d’altro canto, allena BERT a determinare se una frase segue logicamente l’altra, importante per compiti che coinvolgono relazioni tra frasi (Google Research).
Dopo il pre-allenamento, BERT subisce un’ottimizzazione su compiti secondari specifici come risposte a domande, analisi del sentiment o riconoscimento di entità nominate. In questa fase, il modello pre-allenato viene ulteriormente addestrato su un dataset più piccolo e etichettato progettato per il compito target. L’architettura rimane sostanzialmente invariata, ma vengono aggiunti strati specifici per il compito (ad esempio, teste di classificazione) secondo necessità. L’ottimizzazione richiede tipicamente solo pochi epoche e relativamente pochi dati, poiché il modello ha già acquisito una solida comprensione del linguaggio durante il pre-allenamento. Questo approccio a due fasi consente a BERT di raggiungere risultati all’avanguardia in un’ampia gamma di benchmark NLP, dimostrando l’efficacia del trasferimento di apprendimento nei modelli linguistici (Google AI Blog).
BERT vs. Modelli NLP Tradizionali: Cosa lo Differenzia?
BERT (Rappresentazioni degli Encoder Bidirezionali dei Trasformatori) rappresenta un notevole cambiamento rispetto ai modelli tradizionali di Elaborazione del Linguaggio Naturale (NLP), principalmente a causa della sua comprensione bidirezionale del contesto e dell’architettura basata su trasformatori. I modelli NLP tradizionali, come le sacche di parole, i modelli n-gram e i precedenti embedding di parole come Word2Vec o GloVe, tipicamente elaborano il testo in modo unidirezionale o indipendente dal contesto. Ad esempio, modelli come Word2Vec generano vettori di parole basandosi esclusivamente sulle finestre di contesto locali, e le reti neurali ricorrenti (RNN) elaborano sequenze da sinistra a destra o da destra a sinistra, limitando la loro capacità di catturare il contesto completo della frase.
Al contrario, BERT sfrutta un’architettura di trasformatori che gli consente di considerare simultaneamente il contesto a sinistra e a destra per ogni parola in una frase. Questo approccio bidirezionale consente a BERT di generare rappresentazioni di parole più ricche e sensibili al contesto, il che è particolarmente vantaggioso per compiti che richiedono una comprensione sfumata, come risposte a domande e analisi del sentiment. Inoltre, BERT è pre-allenato su ampi corpora utilizzando obiettivi di modellazione del linguaggio mascherato e predizione della prossima frase, consentendo di apprendere caratteristiche sintattiche e semantiche profonde prima di essere ottimizzato su compiti secondari specifici.
Risultati empirici hanno dimostrato che BERT supera costantemente i modelli tradizionali in un’ampia gamma di benchmark NLP, inclusi i dataset GLUE e SQuAD. La sua architettura e il paradigma di addestramento hanno stabilito nuovi standard per il trasferimento di apprendimento in NLP, consentendo ai professionisti di ottenere risultati all’avanguardia con modifiche minime all’architettura specifica del compito. Per ulteriori dettagli, fare riferimento al documento originale di Google AI Language e al repository GitHub di BERT.
Applicazioni nel Mondo Reale: BERT nella Ricerca, nei Chatbot e Oltre
L’impatto trasformativo di BERT sull’elaborazione del linguaggio naturale (NLP) è più evidente nelle sue applicazioni nel mondo reale, in particolare nei motori di ricerca, nei chatbot e in una varietà di altri domini. Nella ricerca, BERT consente ai sistemi di comprendere meglio il contesto e l’intento dietro le query degli utenti, portando a risultati più pertinenti e accurati. Ad esempio, Google ha integrato BERT nei suoi algoritmi di ricerca per migliorare l’interpretazione delle query conversazionali, specialmente quelle che coinvolgono preposizioni e frasi sfumate. Questo avanzamento consente ai motori di ricerca di abbinare le query con i contenuti in un modo che rispecchia più da vicino la comprensione umana.
Nel campo dell’AI conversazionale, BERT ha significativamente migliorato le prestazioni dei chatbot. Sfruttando il suo profondo contesto bidirezionale, i chatbot possono generare risposte più coerenti e contestualmente appropriate, migliorando la soddisfazione e l’engagement degli utenti. Aziende come Microsoft hanno incorporato BERT nelle loro piattaforme di AI conversazionale, consentendo interazioni più naturali ed efficaci nei servizi clienti e nelle applicazioni di assistenti virtuali.
Oltre alla ricerca e ai chatbot, l’architettura di BERT è stata adattata per compiti come analisi del sentiment, classificazione di documenti e risposte a domande. La sua capacità di essere ottimizzato per compiti specifici con dataset relativamente piccoli ha democratizzato l’accesso a NLP all’avanguardia, consentendo a organizzazioni di tutte le dimensioni di implementare capacità avanzate di comprensione del linguaggio. Di conseguenza, BERT continua a guidare l’innovazione in vari settori, dalla sanità alla finanza, consentendo alle macchine di elaborare e interpretare il linguaggio umano con una precisione e una sfumatura senza precedenti.
Limitazioni e Sfide: In Cosa BERT È Carente
Nonostante il suo impatto trasformativo sull’elaborazione del linguaggio naturale, BERT presenta diverse limitazioni e sfide degne di nota. Una delle principali preoccupazioni è la sua intensità computazionale; sia il pre-allenamento che l’ottimizzazione di BERT richiedono risorse hardware significative, rendendolo meno accessibile per organizzazioni con infrastrutture computazionali limitate. La grandezza del modello porta anche a un elevato consumo di memoria e a tempi di inferenza più lunghi, il che può ostacolare il suo utilizzo in ambienti in tempo reale o con risorse limitate (Google AI Blog).
L’architettura di BERT è intrinsecamente limitata a sequenze di input a lunghezza fissa, generalmente massimo 512 token. Questa restrizione presenta sfide per compiti che coinvolgono documenti più lunghi, poiché sono richieste strategie di troncatura o di suddivisione complesse, che possono portare a una perdita di contesto e prestazioni degradate (arXiv). Inoltre, BERT è pre-allenato su grandi corpora generali, che possono comportare prestazioni subottimali su compiti specifici di dominio a meno che non venga effettuata un’ulteriore adattamento al dominio.
Un’altra sfida è l’incapacità di BERT di eseguire ragionamenti o affrontare compiti che richiedono conoscenze del mondo al di là di quelle presenti nei dati di addestramento. Il modello è anche vulnerabile ad attacchi avversari e può produrre output distorti o privi di senso, riflettendo i bias presenti nei dati di addestramento (Istituto Nazionale degli Standard e della Tecnologia (NIST)). Inoltre, l’interpretabilità di BERT rimane limitata, rendendo difficile comprendere o spiegare le sue previsioni, il che è una preoccupazione significativa per applicazioni in domini sensibili come la sanità o il diritto.
Il Futuro di BERT: Innovazioni, Varianti e Cosa Aspettarsi
Sin dalla sua introduzione, le Rappresentazioni degli Encoder Bidirezionali dei Trasformatori (BERT) hanno rivoluzionato l’elaborazione del linguaggio naturale (NLP), ma il campo continua a evolversi rapidamente. Il futuro di BERT è plasmato da innovazioni in corso, dall’emergere di numerose varianti e dall’integrazione di nuove tecniche per affrontare le sue limitazioni. Una direzione importante è lo sviluppo di modelli più efficienti e scalabili. Ad esempio, modelli come DistilBERT e TinyBERT offrono alternative leggere che mantengono gran parte delle prestazioni di BERT riducendo i requisiti computazionali, rendendoli adatti all’implementazione su dispositivi edge e in applicazioni in tempo reale (Hugging Face).
Un’altra tendenza significativa è l’adattamento di BERT per compiti multilingue e specifici di dominio. BERT multilingue (mBERT) e modelli come BioBERT e SciBERT sono progettati per lingue specifiche o domini scientifici, dimostrando la flessibilità dell’architettura di BERT (Google AI Blog). Inoltre, la ricerca si sta concentrando sul miglioramento dell’interpretabilità e della robustezza di BERT, affrontando preoccupazioni riguardanti la trasparenza del modello e le vulnerabilità agli attacchi.
Guardando al futuro, l’integrazione di BERT con altre modalità, come la visione e il parlato, è un’area promettente, come si vede in modelli come VisualBERT e SpeechBERT. Inoltre, l’emergere di modelli pre-allenati su larga scala, come GPT-3 e T5, ha ispirato architetture ibride che combinano i punti di forza della codifica bidirezionale di BERT con capacità generative (Google AI Blog). Con la continua ricerca, si prevede che BERT e i suoi successori giocheranno un ruolo centrale nell’avanzare le capacità dei sistemi AI attraverso applicazioni diverse.
Fonti & Riferimenti
- Google AI Language
- Vaswani et al. (2017)
- Google Research
- Istituto Nazionale degli Standard e della Tecnologia (NIST)
- Hugging Face