בתוך BERT: כיצד ייצוגי קידוד דו-כיווניים מטראנספורמרים מחדש מגדירים את עיבוד השפה הטבעית ומניעים את הדור הבא של יישומי בינה מלאכותית
- מבוא ל-BERT: מקורות ופריצות דרך
- איך BERT עובד: המדע שמאחורי טראנספורמרים דו-כיווניים
- הכשרה מראש ודירוג: תהליך הלמידה בשני שלבים של BERT
- BERT מול מודלים מסורתיים של NLP: מה מבדל אותו?
- יישומים בעולם האמיתי: BERT בחיפוש, צ'אט-בוטים ומעבר לכך
- מגבלות ואתגרים: היכן ש-BERT לא מצליח
- העתיד של BERT: חדשנויות, גירסאות ומה הלאה
- מקורות והפניות
מבוא ל-BERT: מקורות ופריצות דרך
ייצוגי קידוד דו-כיווניים מטראנספורמרים (BERT) מייצגים אבני דרך משמעותיות בהתפתחות עיבוד השפה הטבעית (NLP). הוצג על ידי חוקרים ב- Google AI Language בשנת 2018, BERT שינה באופן יסודי כיצד מכונות מבינות שפה על ידי ניצול הכוח של טראנספורמרים דו-כיווניים עמוקים. בניגוד למודלים קודמים שעיבדו טקסט הן משמאל לימין והן מימין לשמאל, הארכיטקטורה של BERT מאפשרת לה לשקול את הקשר המלא של מילה על ידי בחינה של הסביבה משמאל ומימין בו-זמנית. גישה דו-כיוונית זו מאפשרת הבנה יותר מעודנת של השפה, תוך תפיסת קשרים ודקויות שנוטות מודלים חד-כיווניים להזניח.
מוצא BERT טמון בארכיטקטורת הטראנספורמר, שהוצגה לראשונה על ידי Vaswani et al. (2017), אשר מתבססת על מנגנוני תשומת לב עצמית לעיבוד רצפים של קלט במקביל. על ידי הכשרה מראש על מאגרי מידע עצומים כמו וויקיפדיה ו-BooksCorpus, BERT לומד ייצוגי שפה כלליים שיכולים להיות מסוננים למשימות שונות, כולל מענה על שאלות, ניתוח רגשות וזיהוי ישויות בשם. שחרור BERT הציב רמות חדשות בסטנדרטים של משימות NLP שונות, כשהוא מצליח לעבור על מודלים קודמים והניע גל של מחקר על ארכיטקטורות מבוססות טראנספורמרים.
הפריצות דרך שהושגו על ידי BERT לא רק שהקדימו את המחקר האקדמי אלא גם הובילו לשיפורים מעשיים ביישומים מסחריים, כמו מנועי חיפוש ועוזרים וירטואליים. השחרור שלה כ"קוד פתוח" הדמוקרטי את הגישה למודלים רבי עוצמה, ועודד חדשנות ושיתוף פעולה ברחבי קהילת NLP.
איך BERT עובד: המדע שמאחורי טראנספורמרים דו-כיווניים
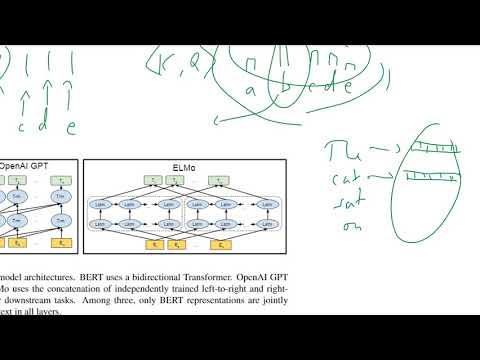
החדשנות המרכזית של BERT טמונה בשימוש בטראנספורמרים דו-כיווניים, שמשנים באופן יסודי כיצד מודלים של שפה מבינים הקשר. בניגוד למודלים המסורתיים שמעבדים טקסט משמאל לימין או מימין לשמאל, BERT עושה שימוש בארכיטקטורת טראנספורמר כדי לנתח את כל המילים במשפט בו-זמנית, תוך שתשקול גם מילים קודמות וגם מילים עוקבות. גישה דו-כיוונית זו מאפשרת ל-BERT לתפוס קשרים ודיבורונית בשפה, ובסופו של דבר להוביל להבנה מעמיקה יותר של משמעות והקשר.
המדע שמאחורי הדו-כיווניות של BERT טמון במטלות ההכשרה מראש שלו: מודל שפה במסך (MLM) וחיזוי המשפט הבא (NSP). ב-MLM, מילים אקראיות במשפט מוסכות, והמודל לומד לחזות את הטוקנים המסוכנים הללו על ידי בחינת ההקשר הפנוי משני הצדדים. זה בניגוד למודלים קודמים, שיכלו להשתמש רק בהקשר חלקי, והגביל את ההבנה שלהם. NSP, מנגד, מאמן את BERT להבין את הקשר בין זוגות של משפטים, וכך משפר את תפיסת ההקשר והקוהרנטיות שלה.
הארכיטקטורה של BERT מבוססת על קידוד טראנספורמר, שמשתמש במנגנוני תשומת לב עצמית כדי למדוד את חשיבות כל מילה בהשוואה לאחרות בקלט. זה מאפשר ל-BERT לדגם תופעות לשוניות מורכבות כמו פולי-משמעות ותלויות ארוכות טווח. התוצאה היא מודל שמגיע לביצועים ברמה הגבוהה ביותר במספר רב של משימות בעיבוד שפה טבעית, כולל מענה על שאלות וניתוח רגשות. למידע טכני מפורט, עיינו במאמר המקורי של Google AI Language ובמסמכים הרשמיים מ-Google Research.
הכשרה מראש ודירוג: תהליך הלמידה בשני שלבים של BERT
הביצועים המרשימים של BERT במשימות עיבוד שפה טבעית נובעים בעיקר מתהליך הלמידה הייחודי בשני השלבים שלו: הכשרה מראש ודירוג. במהלך שלב ההכשרה מראש, BERT נחשף לנפחים עצומים של טקסט לא ממוספר, לומד ייצוגי שפה כלליים באמצעות שתי משימות עצמאיות: מודל שפה במסך (MLM) וחיזוי המשפט הבא (NSP). ב-MLM, מילים אקראיות במשפט מוסכות, והמודל לומד לחזות את הטוקנים המסוכנים הללו על סמך ההקשר שלהם, מה שמאפשר הבנה דו-כיוונית עמוקה. NSP, מנגד, מאמן את BERT לקבוע האם משפט אחד מתנהל באופן לוגי אחרי אחר, דבר שחיוני למשימות שכוללות קשרים בין משפטים (Google Research).
לאחר הכשרה מראש, BERT עובר דירוג על משימות מסוימות כמו מענה על שאלות, ניתוח רגשות או זיהוי ישויות בשם. בשלב זה, המודל המוכשר מראש מתאמן שוב על מסד נתונים קטן ומסומן המיועד למשימה המיועדת. הארכיטקטורה נשארת בעיקרה זהה, אך שכבות המיועדות למשימות (למשל, שכבות סיווג) מתווספות לפי הצורך. דירוג בדרך כלל דורש רק מספר מופעים ומעט מאוד נתונים, כיוון שהמודל כבר רכש הבנה מוצקה של השפה במהלך ההכשרה מראש. גישה זו בשני שלבים מאפשרת ל-BERT להשיג תוצאות ברמה הגבוהה ביותר במגוון רחב של מדדי NLP, ובכך מדגימה את האפקטיביות של למידת העברת בהפקות שפה (Google AI Blog).
BERT מול מודלים מסורתיים של NLP: מה מבדל אותו?
BERT (ייצוגי קידוד דו-כיווניים מטראנספורמרים) מייצג שינוי משמעותי מהמודלים המסורתיים של עיבוד שפה טבעית (NLP), בעיקר בשל הבנת הקונטקסט הדו-כיוונית שלו והארכיטקטורה המבוססת על טראנספורמרים. מודלים מסורתיים של NLP, כמו תיקי מילים, מודלי n-gram, והטבעות המוקדמות כמו Word2Vec או GloVe, בדרך כלל מעבדים טקסט באופן חד-כיווני או בלתי תלוי בקונטקסט. לדוגמה, מודלים כמו Word2Vec מייצרים וקטורי מילים בהתבסס רק על חלונות הקשר מקומיים, ורשתות עצביות חוזרות (RNNs) מעבדות רצפים או משמאל לימין או מימין לשמאל, מה שמגביל את היכולת שלהם לתפוס את הקשר המלא של המשפט.
בניגוד לכך, BERT משתמש בארכיטקטורת טראנספורמר שמאפשרת לו לשקול את שני ההקשרים בו זמנית עבור כל מילה במשפט. גישה דו-כיוונית זו מאפשרת ל-BERT לייצר ייצוגים עשירים, רגישים להקשר של מילים, דבר שהוא יתרון במיוחד למשימות שדורשות הבנה מעודנת, כמו מענה על שאלות וניתוח רגשות. יתרה מכך, BERT מוכשר מראש על מאגרי מידע גדולים באמצעות מטרות של מודל שפה במסך וחיזוי המשפט הבא, מה שמאפשר לו ללמוד תכנים סמנטיים וסינתקטיים עמוקים לפני דירוג על משימות מטרה ספציפיות.
תוצאות אמפיריות הוכיחו כי BERT בצורה עקבית מתעלה על מודלים מסורתיים במגוון רחב של מדדי NLP, כולל מאגרי GLUE ו-SQuAD. הארכיטקטורה שלו ופראדיגמת ההכשרה שלו קובעות סטנדרטים חדשים ללמידת העברה ב-NLP, מה שמאפשר למבצעי NLP להשיג תוצאות ברמה הגבוהה ביותר עם שינויים מינימליים באדריכלות המיועדת. למידע נוסף, אנא עיינו במאמר המקורי של Google AI Language ובמסמכי הBERT GitHub הרשמית.
יישומים בעולם האמיתי: BERT בחיפוש, צ'אט-בוטים ומעבר לכך
ההשפעה המהפכנית של BERT על עיבוד השפה הטבעית (NLP) ניכרת ביותר ביישומים בעולם האמיתי, במיוחד במנועי חיפוש, צ'אט-בוטים ומגוון תחומים אחרים. בחיפוש, BERT מאפשר למערכות להבין טוב יותר את ההקשר והכוונה מאחורי שאילתות המשתמש, מה שמוביל לתוצאות רלוונטיות ומדויקות יותר. לדוגמה, Google שילבה את BERT באלגוריטמים שלה כדי לשפר את הפרשנות של שאילתות שיחה, במיוחד כאלו שכוללות מילים שנמצאות ביחד וביטויים מעודנים. פיתוח זה מאפשר למנועי חיפוש להתאים בין שאילתות לתוכן בדרך הקרובה יותר להבנת האדם.
בתחום ה-AI השיחתי, BERT שיפר במידה ניכרת את ביצועי הצ'אט-בוטים. באמצעות ניצול הקשר הדו-כיווני העמוק שלו, הצ'אט-בוטים יכולים לייצר תגובות יותר קוהרנטיות ונכונות להקשר, ובכך לשפר את שביעות רצון המשתמשים והמעורבות. חברות כמו מיקרוסופט השיבו את BERT לפלטפורמות ה-AI השיחתי שלהן, מה שמאפשר אינטראקציות יותר טבעיות ויעילות בשירות לקוחות וביישומים של עוזרים וירטואליים.
מעבר לחיפוש וצ'אט-בוטים, הארכיטקטורה של BERT הותאמה למשימות כמו ניתוח רגשות, סיווג מסמכים, ומענה על שאלות. היכולת שלו להסתנכרן עם משימות ספציפיות באמצעות קבוצות נתונים קטנות יחסית הפכה את הגישה למודלים ברמה הגבוהה ביותר של NLP לנגישה, מה שאיפשר לארגונים בכל הגדלים להפעיל יכולות מתקדמות של הבנת שפה. כתוצאה מכך, BERT ממשיך לדרבן חדשנות בעולמות שונים, מהבריאות ועד הכספים, על ידי מתן אפשרות למכונות לעבד ולפרש שפה אנושית בדיוק ובדקויות שלא נראו כמותם.
מגבלות ואתגרים: היכן ש-BERT לא מצליח
למרות השפעתו המהפכנית על עיבוד השפה הטבעית, ל-BERT יש כמה מגבלות ואתגרים בולטים. אחת הדאגות העיקריות היא האינטנסיביות החישובית שלו; הן הכשרה מראש והן דירוג של BERT דורשות משאבי חומרה משמעותיים, מה שהופך את הגישה אליו לפחות נגישה עבור ארגונים עם תשתית חישוב מוגבלת. גודלו הגדול של המודל גם מביא לצריכת זיכרון גבוהה וזמני אינפרציה איטיים, דבר שעלול להקשות על הפעלתו בסביבות חיות או עם משאבים מוגבלים (Google AI Blog).
הארכיטקטורה של BERT מוגבלת באופן טבעי לרצפי קלט באורך קבוע, בדרך כלל מוגבל ל-512 טוקנים. הגבלה זו מציבה אתגרים למשימות הכוללות מסמכים ארוכים יותר, שכן דרושים קיצורים או אסטרטגיות חיתוך מורכבות, דבר שעשוי להוביל לאובדן הקשר ולביצועים ירודים (arXiv). בנוסף, BERT מאומן מראש על מאגרי נתונים גדולים ובעלי תחום כללי, דבר שעלול לגרום לביצועים לא אופטמליים במשימות ספציפיות של תחום אלא אם יבוצע התאמה של התחום.
אתגר נוסף הוא חוסר היכולת של BERT לבצע תהליכי היגיון או לטפל במשימות שמצריכות ידע על העולם מעבר למה שנמצא בנתוני האימון שלו. המודל גם פגיע להתקפות עוינות ועשוי לייצר פלטים מפלים או חסרי משמעות, המבטאים הטיות שהיו קיימות בנתוני האימון שלו (המכון הלאומי לתקנים וטכנולוגיה (NIST)). בנוסף, ההסברציות של BERT עדיין מוגבלות, מה שמקשה על הבנת או הסברת התחזיות שלו, דבר שמדאיג במיוחד ביישומים בתחומים רגישים כמו בריאות או משפטים.
העתיד של BERT: חדשנויות, גירסאות ומה הלאה
מאז ההצגה שלו, ייצוגי קידוד דו-כיווניים מטראנספורמרים (BERT) הפכו את עיבוד השפה הטבעית (NLP) למהפכני, אך התחום ממשיך להתפתח במהירות. העתיד של BERT מעוצב על ידי חדשנויות נמשכות, הופעתן של גירסאות רבות, ושילוב של טכניקות חדשות כדי להתמודד עם המגבלות שלו. כיוון מרכזי אחד הוא הפיתוח של מודלים יותר יעילים ומס Scalel. למשל, מודלים כמו DistilBERT ו-TinyBERT מציעים חלופות קלות שממשיכות לשמור על הרבה מהביצועים של BERT תוך הפחתת הדרישות החישוביות, מה שהופך אותם המתאימים להפעיל על מכשירים קצה וביישומים בזמן אמת (Hugging Face).
טרנד נוסף משמעותי הוא ההתאמה של BERT למשימות רב-לשוניות ותחום. BERT רב-לשוני (mBERT) ומודלים כמו BioBERT ו-SciBERT מותאמים לשפות או תחומים מדעיים מסוימים, מה שמדגים את הגמישות של ארכיטקטורת BERT (Google AI Blog). בנוסף, יש מחקר שמתמקד בשיפור ההסבר הפנימי והקשיחות של BERT, מגיב לדאגות אודות שקיפות המודל ופגיעות עוינות.
בהסתכלות קדימה, שילוב של BERT יחד עם מודאליות אחרות, כגון ראיה ודיבור, הוא תחום מבטיח, כפי שנראה במודלים כמו VisualBERT ו-SpeechBERT. יתרה מכך, עליית מודלים גדולים המוכשרים מראש, כמו GPT-3 ו-T5, השרתה אדריכלות מעורבבת שמשלבת את היתרונות של הקידוד הדו-כיווני של BERT עם יכולות גנרטיביות (Google AI Blog). ככל שהמחקר נמשך, BERT וההמשכיות שלו צפויים לשחק תפקיד מרכזי בהתקדמות היכולות של מערכות AI באפליקציות שונות.
מקורות והפניות
- Google AI Language
- Vaswani et al. (2017)
- Google Research
- המכון הלאומי לתקנים וטכנולוגיה (NIST)
- Hugging Face