Dentro de BERT: Cómo las Representaciones de Codificador Bidireccionales de Transformadores Están Redefiniendo el Procesamiento del Lenguaje Natural y Potenciando la Próxima Generación de Aplicaciones de IA
- Introducción a BERT: Orígenes y Avances
- Cómo Funciona BERT: La Ciencia Detrás de los Transformadores Bidireccionales
- Preentrenamiento y Ajuste Fino: El Proceso de Aprendizaje de Dos Etapas de BERT
- BERT vs. Modelos NLP Tradicionales: ¿Qué lo Hace Diferente?
- Aplicaciones del Mundo Real: BERT en Búsqueda, Chatbots y Más
- Limitaciones y Desafíos: ¿Dónde No Llega BERT?
- El Futuro de BERT: Innovaciones, Variantes y Qué Viene a Continuación
- Fuentes y Referencias
Introducción a BERT: Orígenes y Avances
Las Representaciones de Codificador Bidireccionales de Transformadores (BERT) representan un hito significativo en la evolución del procesamiento del lenguaje natural (NLP). Introducido por investigadores de Google AI Language en 2018, BERT cambió fundamentalmente la forma en que las máquinas entienden el lenguaje al aprovechar el poder de los transformadores bidireccionales profundos. A diferencia de los modelos anteriores que procesaban texto de izquierda a derecha o de derecha a izquierda, la arquitectura de BERT le permite considerar el contexto completo de una palabra al observar simultáneamente tanto sus alrededores a la izquierda como a la derecha. Este enfoque bidireccional permite una comprensión más matizada del lenguaje, capturando relaciones sutiles y significados que los modelos unidireccionales a menudo pasan por alto.
Los orígenes de BERT están en la arquitectura del transformador, introducida por primera vez por Vaswani et al. (2017), que se basa en mecanismos de autoatención para procesar secuencias de entrada en paralelo. Al preentrenarse en grandes corpus como Wikipedia y BooksCorpus, BERT aprende representaciones generales del lenguaje que pueden ajustarse finamente para una amplia gama de tareas posteriores, incluyendo respuesta a preguntas, análisis de sentimientos y reconocimiento de entidades nombradas. El lanzamiento de BERT estableció nuevos puntos de referencia en múltiples tareas de NLP, superando a los modelos de última generación anteriores e inspirando una ola de investigación en arquitecturas basadas en transformadores.
Los avances logrados por BERT no solo han promovido la investigación académica, sino que también han llevado a mejoras prácticas en aplicaciones comerciales, como motores de búsqueda y asistentes virtuales. Su lanzamiento como código abierto ha democratizado el acceso a modelos de lenguaje potentes, fomentando la innovación y la colaboración en toda la comunidad de NLP.
Cómo Funciona BERT: La Ciencia Detrás de los Transformadores Bidireccionales
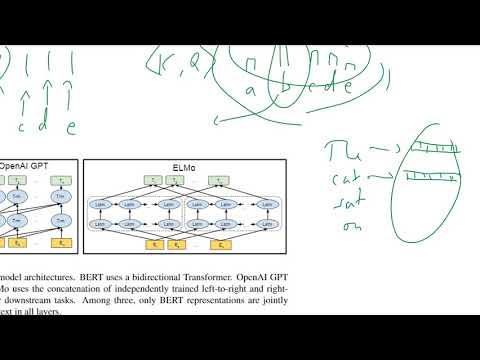
La innovación central de BERT radica en su uso de transformadores bidireccionales, que cambian fundamentalmente la forma en que los modelos de lenguaje entienden el contexto. A diferencia de los modelos tradicionales que procesan texto de izquierda a derecha o de derecha a izquierda, BERT aprovecha una arquitectura de transformador para analizar todas las palabras en una oración simultáneamente, considerando tanto las palabras precedentes como las siguientes. Este enfoque bidireccional permite que BERT capture relaciones y dependencias matizadas dentro del lenguaje, lo que lleva a una comprensión más profunda del significado y el contexto.
La ciencia detrás de la bidireccionalidad de BERT se basa en sus tareas de preentrenamiento: Modelado de Lenguaje Enmascarado (MLM) y Predicción de la Siguiente Oración (NSP). En MLM, se enmascaran palabras aleatorias en una oración, y el modelo aprende a predecir estos tokens enmascarados al considerar todo el contexto a ambos lados. Esto contrasta con los modelos anteriores, que solo podían utilizar contextos parciales, limitando su comprensión. NSP, por otro lado, entrena a BERT para entender la relación entre pares de oraciones, mejorando aún más su comprensión del contexto y la coherencia.
La arquitectura de BERT se basa en el codificador de transformadores, que utiliza mecanismos de autoatención para ponderar la importancia de cada palabra en relación con las demás en la entrada. Esto permite a BERT modelar fenómenos lingüísticos complejos como la polisemia y las dependencias a largo plazo. El resultado es un modelo que alcanza un rendimiento de última generación en una amplia gama de tareas de procesamiento del lenguaje natural, incluyendo la respuesta a preguntas y el análisis de sentimientos. Para una visión técnica detallada, consulte el documento original de Google AI Language y la documentación oficial de Google Research.
Preentrenamiento y Ajuste Fino: El Proceso de Aprendizaje de Dos Etapas de BERT
El notable rendimiento de BERT en tareas de procesamiento del lenguaje natural se atribuye en gran medida a su innovador proceso de aprendizaje de dos etapas: preentrenamiento y ajuste fino. Durante la fase de preentrenamiento, BERT se expone a grandes cantidades de texto no etiquetado, aprendiendo representaciones generales del lenguaje a través de dos tareas de auto-supervisión: Modelado de Lenguaje Enmascarado (MLM) y Predicción de la Siguiente Oración (NSP). En MLM, se enmascaran palabras aleatorias en una oración, y el modelo aprende a predecir estos tokens enmascarados según su contexto, permitiendo una comprensión bidireccional profunda. NSP, por otro lado, entrena a BERT para determinar si una oración sigue lógicamente a otra, lo que es crucial para tareas que implican relaciones entre oraciones (Google Research).
Después del preentrenamiento, BERT pasa por un ajuste fino en tareas específicas posteriores, como la respuesta a preguntas, el análisis de sentimientos o el reconocimiento de entidades nombradas. En esta etapa, el modelo preentrenado se entrena aún más en un conjunto de datos etiquetado más pequeño, adaptado a la tarea objetivo. La arquitectura permanece en gran medida sin cambios, pero se agregan capas específicas de la tarea (por ejemplo, cabezales de clasificación) según sea necesario. El ajuste fino típicamente requiere solo unas pocas épocas y relativamente pocos datos, ya que el modelo ya ha adquirido una comprensión robusta del lenguaje durante el preentrenamiento. Este enfoque de dos etapas permite a BERT lograr resultados de última generación en una amplia gama de estándares de NLP, demostrando la efectividad del aprendizaje por transferencia en modelos de lenguaje (Google AI Blog).
BERT vs. Modelos NLP Tradicionales: ¿Qué lo Hace Diferente?
BERT (Representaciones de Codificador Bidireccionales de Transformadores) representa un cambio significativo respecto a los modelos tradicionales de Procesamiento del Lenguaje Natural (NLP), principalmente debido a su comprensión del contexto bidireccional y su arquitectura basada en transformadores. Los modelos NLP tradicionales, como bolsa de palabras, modelos n-gram y embeddings de palabras anteriores como Word2Vec o GloVe, típicamente procesan texto de manera unidireccional o independiente del contexto. Por ejemplo, modelos como Word2Vec generan vectores de palabras basándose únicamente en ventanas de contexto locales, y las redes neuronales recurrentes (RNN) procesan secuencias de izquierda a derecha o de derecha a izquierda, limitando su capacidad para capturar el contexto completo de la oración.
En contraste, BERT aprovecha una arquitectura de transformador que le permite considerar tanto el contexto a la izquierda como el de la derecha simultáneamente para cada palabra en una oración. Este enfoque bidireccional permite que BERT genere representaciones más ricas y sensibles al contexto de las palabras, lo cual es particularmente ventajoso para tareas que requieren comprensión matizada, como la respuesta a preguntas y el análisis de sentimientos. Además, BERT es preentrenado en grandes corpus utilizando objetivos de modelado de lenguaje enmascarado y predicción de la siguiente oración, lo que le permite aprender características semánticas y sintácticas profundas antes de ser ajustado finamente en tareas específicas posteriores.
Los resultados empíricos han demostrado que BERT supera consistentemente a modelos tradicionales en una amplia gama de estándares de NLP, incluyendo los conjuntos de datos GLUE y SQuAD. Su arquitectura y paradigma de entrenamiento han establecido nuevos estándares para el aprendizaje por transferencia en NLP, permitiendo a los profesionales lograr resultados de última generación con modificaciones mínimas en la arquitectura específica de la tarea. Para más detalles, consulte el documento original de Google AI Language y el repositorio oficial de BERT en GitHub.
Aplicaciones del Mundo Real: BERT en Búsqueda, Chatbots y Más
El impacto transformador de BERT en el procesamiento del lenguaje natural es más evidente en sus aplicaciones del mundo real, particularmente en motores de búsqueda, chatbots y una variedad de otros dominios. En la búsqueda, BERT permite a los sistemas comprender mejor el contexto y la intención detrás de las consultas de los usuarios, conduciendo a resultados más relevantes y precisos. Por ejemplo, Google integró BERT en sus algoritmos de búsqueda para mejorar la interpretación de consultas conversacionales, especialmente aquellas que involucran preposiciones y formulaciones matizadas. Este avance permite que los motores de búsqueda emparejen consultas con contenido de una manera que se asemeja más a la comprensión humana.
En el ámbito de la IA conversacional, BERT ha mejorado significativamente el rendimiento de los chatbots. Al aprovechar su contexto bidireccional profundo, los chatbots pueden generar respuestas más coherentes y apropiadas al contexto, mejorando la satisfacción y el compromiso del usuario. Empresas como Microsoft han incorporado BERT en sus plataformas de IA conversacional, permitiendo interacciones más naturales y efectivas en aplicaciones de servicio al cliente y asistentes virtuales.
Más allá de la búsqueda y los chatbots, la arquitectura de BERT se ha adaptado para tareas como análisis de sentimientos, clasificación de documentos y respuesta a preguntas. Su capacidad de ser ajustado finamente para tareas específicas con conjuntos de datos relativamente pequeños ha democratizado el acceso a NLP de última generación, permitiendo a organizaciones de todos los tamaños desplegar capacidades avanzadas de comprensión del lenguaje. Como resultado, BERT sigue impulsando la innovación en diversas industrias, desde la atención médica hasta las finanzas, al permitir que las máquinas procesen e interpreten el lenguaje humano con una precisión y matices sin precedentes.
Limitaciones y Desafíos: ¿Dónde No Llega BERT?
A pesar de su impacto transformador en el procesamiento del lenguaje natural, BERT exhibe varias limitaciones y desafíos notables. Una preocupación principal es su intensidad computacional; tanto el preentrenamiento como el ajuste fino de BERT requieren recursos de hardware significativos, haciéndolo menos accesible para organizaciones con infraestructura computacional limitada. El gran tamaño del modelo también conduce a un alto consumo de memoria y tiempos de inferencia más lentos, lo que puede obstaculizar el despliegue en entornos en tiempo real o con recursos limitados (Google AI Blog).
La arquitectura de BERT está inherentemente limitada a secuencias de entrada de longitud fija, típicamente limitadas a 512 tokens. Esta restricción plantea desafíos para tareas que involucran documentos más largos, ya que se requieren estrategias de truncamiento o división complejas, lo que puede llevar a la pérdida de contexto y a un rendimiento degradado (arXiv). Además, BERT se preentrena en grandes corpus de dominio general, lo que puede resultar en un rendimiento subóptimo en tareas específicas de dominio a menos que se realice una adaptación adicional al dominio.
Otro desafío es la incapacidad de BERT para razonar o manejar tareas que requieren conocimiento del mundo más allá de lo que está presente en sus datos de entrenamiento. El modelo también es susceptible a ataques adversariales y puede producir resultados sesgados o sin sentido, reflejando sesgos presentes en sus datos de entrenamiento (Instituto Nacional de Estándares y Tecnología (NIST)). Además, la interpretabilidad de BERT sigue siendo limitada, lo que dificulta entender o explicar sus predicciones, lo cual es una preocupación significativa para aplicaciones en dominios sensibles como la atención médica o la ley.
El Futuro de BERT: Innovaciones, Variantes y Qué Viene a Continuación
Desde su introducción, las Representaciones de Codificador Bidireccionales de Transformadores (BERT) han revolucionado el procesamiento del lenguaje natural, pero el campo continúa evolucionando rápidamente. El futuro de BERT está moldeado por innovaciones en curso, la aparición de numerosas variantes y la integración de nuevas técnicas para abordar sus limitaciones. Una dirección importante es el desarrollo de modelos más eficientes y escalables. Por ejemplo, modelos como DistilBERT y TinyBERT ofrecen alternativas ligeras que mantienen gran parte del rendimiento de BERT mientras reducen los requisitos computacionales, haciéndolos aptos para su implementación en dispositivos de borde y en aplicaciones en tiempo real (Hugging Face).
Otra tendencia significativa es la adaptación de BERT para tareas multilingües y específicas de dominio. BERT multilingüe (mBERT) y modelos como BioBERT y SciBERT están diseñados para idiomas específicos o dominios científicos, demostrando la flexibilidad de la arquitectura de BERT (Google AI Blog). Además, la investigación se centra en mejorar la interpretabilidad y robustez de BERT, abordando preocupaciones sobre la transparencia del modelo y la vulnerabilidad a ataques adversariales.
Mirando hacia el futuro, la integración de BERT con otras modalidades, como visión y habla, es un área prometedora, como se ha visto en modelos como VisualBERT y SpeechBERT. Además, el auge de modelos preentrenados a gran escala, como GPT-3 y T5, ha inspirado arquitecturas híbridas que combinan las fortalezas de la codificación bidireccional de BERT con capacidades generativas (Google AI Blog). A medida que la investigación continúa, se espera que BERT y sus sucesores desempeñen un papel central en el avance de las capacidades de los sistemas de IA en diversas aplicaciones.
Fuentes y Referencias
- Google AI Language
- Vaswani et al. (2017)
- Google Research
- Instituto Nacional de Estándares y Tecnología (NIST)
- Hugging Face