Μέσα στο BERT: Πώς οι Διεύθυνες Κωδικοποιήσεις από Transformers Επαναστατούν την Επεξεργασία Φυσικής Γλώσσας και Ενισχύουν την Επόμενη Γενιά Εφαρμογών Τεχνητής Νοημοσύνης
- Εισαγωγή στο BERT: Οι Ρίζες και οι Επαναστάσεις
- Πώς Λειτουργεί το BERT: Η Επιστήμη πίσω από τους Διευθυντικούς Transformers
- Προεκπαίδευση και Χοντροκόπημα: Η Διφασική Διαδικασία Εκπαίδευσης του BERT
- BERT vs. Παραδοσιακά Μοντέλα NLP: Τι το Διαχωρίζει;
- Πραγματικές Εφαρμογές: Το BERT στην Αναζήτηση, τα Chatbots και Πέρα από Αύτα
- Περιορισμοί και Προκλήσεις: Πού Υστερεί το BERT
- Το Μέλλον του BERT: Καινοτομίες, Παραλλαγές και Τι Ακολουθεί
- Πηγές & Αναφορές
Εισαγωγή στο BERT: Οι Ρίζες και οι Επαναστάσεις
Οι Διεύθυνες Κωδικοποιήσεις από Transformers (BERT) αντιπροσωπεύουν μια σημαντική ορόσημο στην εξέλιξη της επεξεργασίας φυσικής γλώσσας (NLP). Εισήχθη από ερευνητές της Google AI Language το 2018, το BERT άλλαξε θεμελιωδώς τον τρόπο που οι μηχανές κατανοούν τη γλώσσα αξιοποιώντας τη δύναμη των βαθιών διεύθυνων transformers. Σε αντίθεση με προηγούμενα μοντέλα που επεξεργάζονταν το κείμενο είτε από αριστερά προς τα δεξιά είτε από δεξιά προς τα αριστερά, η αρχιτεκτονική του BERT του επιτρέπει να εξετάζει το πλήρες περιβάλλον μιας λέξης, κοιτάζοντας ταυτόχρονα και το αριστερό και το δεξί της πλαίσιο. Αυτή η διευθυντική προσέγγιση επιτρέπει μια πιο λεπτομερή κατανόηση της γλώσσας, καταγράφοντας τις λεπτές σχέσεις και τις έννοιες που συχνά παραλείπουν τα μοντέλα που λειτουργούν μονόδρομα.
Οι ρίζες του BERT βρίσκονται στην αρχιτεκτονική των transformers, η οποία παρουσιάστηκε για πρώτη φορά από Vaswani et al. (2017), και βασίζεται σε μηχανισμούς αυτοπροσοχής για την επεξεργασία των εισερχόμενων ακολουθιών παράλληλα. Μέσω της προεκπαίδευσης σε τεράστιες συλλογές κειμένων όπως η Wikipedia και το BooksCorpus, το BERT μαθαίνει γενικές αναπαραστάσεις γλώσσας που μπορούν να προσαρμοστούν για μια ευρεία γκάμα εργασιών, συμπεριλαμβανομένων των ερωτήσεων απάντησης, της ανάλυσης συναισθήματος και της αναγνώρισης ονομάτων. Η κυκλοφορία του BERT καθόρισε νέα πρότυπα σε πολλές εργασίες NLP, ξεπερνώντας προηγμένα μοντέλα και εμπνέοντας μια σειρά ερευνών γύρω από τις αρχιτεκτονικές βασισμένες σε transformers.
Οι επαναστάσεις που επιτεύχθηκαν από το BERT έχουν προωθήσει όχι μόνο την ακαδημαϊκή έρευνα αλλά και πρακτικές βελτιώσεις σε εμπορικές εφαρμογές, όπως οι μηχανές αναζήτησης και οι εικονικοί βοηθοί. Η ανοιχτή του ανακαίνιση έχει δημοκρατήσει την πρόσβαση σε ισχυρά γλωσσικά μοντέλα, προάγοντας την καινοτομία και τη συνεργασία σε όλη την κοινότητα του NLP.
Πώς Λειτουργεί το BERT: Η Επιστήμη πίσω από τους Διευθυντικούς Transformers
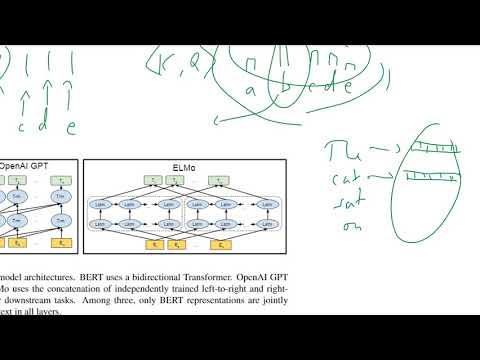
Η κύρια καινοτομία του BERT έγκειται στη χρήση διευθυντικών transformers, που αλλάζουν θεμελιωδώς τον τρόπο που τα γλωσσικά μοντέλα κατανοούν το πλαίσιο. Σε αντίθεση με παραδοσιακά μοντέλα που επεξεργάζονται το κείμενο είτε αριστερά προς τα δεξιά είτε δεξιά προς τα αριστερά, το BERT αξιοποιεί μια αρχιτεκτονική transformer για να αναλύσει όλες τις λέξεις σε μια πρόταση ταυτόχρονα, μελετώντας τόσο τις προηγούμενες όσο και τις επόμενες λέξεις. Αυτή η διευθυντική προσέγγιση επιτρέπει στο BERT να καταγράφει λεπτές σχέσεις και εξαρτήσεις στη γλώσσα, οδηγώντας σε μια βαθύτερη κατανόηση της σημασίας και του πλαισίου.
Η επιστήμη πίσω από τη διευθυντικότητα του BERT βασίζεται στις εργασίες προεκπαίδευσής του: Μοντελοποίηση Μάσκας Γλώσσας (MLM) και Πρόβλεψη Επόμενης Πρότασης (NSP). Στο MLM, οι τυχαίες λέξεις σε μια πρόταση καλύπτονται, και το μοντέλο μαθαίνει να προβλέπει αυτούς τους καλυμμένους δείκτες αναλογιζόμενο το πλήρες πλαίσιο και από τις δύο πλευρές. Αυτό αντίκειται στα προηγούμενα μοντέλα, τα οποία μπορούσαν να χρησιμοποιούν μόνο μερικό πλαίσιο, περιορίζοντας τη κατανόησή τους. Η NSP, από την άλλη μεριά, εκπαιδεύει το BERT να κατανοήσει τη σχέση μεταξύ ζευγών προτάσεων, ενισχύοντας περαιτέρω την κατανόησή του για το πλαίσιο και τη συνοχή.
Η αρχιτεκτονική του BERT βασίζεται στον κωδικοποιητή transformer, ο οποίος χρησιμοποιεί μηχανισμούς αυτοπροσοχής για να εκτιμήσει τη σημασία κάθε λέξης σε σχέση με άλλες στην είσοδο. Αυτό επιτρέπει στο BERT να μοντελοποιεί σύνθετα γλωσσικά φαινόμενα όπως η πολυσημία και οι μακροχρόνιες εξαρτήσεις. Το αποτέλεσμα είναι ένα μοντέλο που πετυχαίνει κορυφαία απόδοση σε μια ευρεία γκάμα εργασιών επεξεργασίας φυσικής γλώσσας, συμπεριλαμβανομένων των ερωτήσεων απάντησης και της ανάλυσης συναισθήματος. Για μια λεπτομερή τεχνική επισκόπηση, ανατρέξτε στο πρωτότυπο άρθρο από την Google AI Language και την επίσημη τεκμηρίωση από την Google Research.
Προεκπαίδευση και Χοντροκόπημα: Η Διφασική Διαδικασία Εκπαίδευσης του BERT
Η Remarkable απόδοση του BERT σε εργασίες επεξεργασίας φυσικής γλώσσας οφείλεται σε μεγάλο βαθμό στη καινοτόμο διφασική διαδικασία εκπαίδευσής του: προεκπαίδευση και χοντροκόπημα. Κατά τη διάρκεια της προεκπαίδευσης, το BERT εκτίθεται σε τεράστιες ποσότητες μη επισημασμένου κειμένου, μαθαίνοντας γενικές αναπαραστάσεις γλώσσας μέσω δύο αυτοεπιβλεπόμενων εργασιών: Μοντελοποίησης Μάσκας Γλώσσας (MLM) και Πρόβλεψης Επόμενης Πρότασης (NSP). Στο MLM, οι τυχαίες λέξεις σε μια πρόταση καλύπτονται, και το μοντέλο μαθαίνει να προβλέπει αυτούς τους καλυμμένους δείκτες αναλογιζόμενο το πλαίσιο τους, επιτρέποντας βαθιά διευθυντική κατανόηση. Η NSP, από την άλλη πλευρά, εκπαιδεύει το BERT να καθορίζει εάν μια πρόταση λογικά ακολουθεί μια άλλη, το οποίο είναι ζωτικής σημασίας για εργασίες που περιλαμβάνουν σχέσεις προτάσεων (Google Research).
Αφού προεκπαιδευτεί, το BERT υποβάλλεται σε χοντροκόπημα σε συγκεκριμένες εργασίες, όπως ερωτήσεις απάντησης, ανάλυση συναισθήματος ή αναγνώριση ονομάτων. Σε αυτή τη φάση, το προεκπαιδευμένο μοντέλο εκπαιδεύεται περαιτέρω σε ένα μικρότερο, επισημασμένο σύνολο δεδομένων προσαρμοσμένο στην στοχευόμενη εργασία. Η αρχιτεκτονική παραμένει σε μεγάλο βαθμό αμετάβλητη, αλλά προστίθενται ανάγκες ειδικές για την εργασία (π.χ. κεφάλες κατηγοριοποίησης) κατά περίπτωση. Η διαδικασία χοντροκοπήματος συνήθως απαιτεί μόνο μερικές εποχές και σχετικά λίγα δεδομένα, καθώς το μοντέλο έχει ήδη αποκτήσει μια ισχυρή κατανόηση της γλώσσας κατά την προεκπαίδευση. Αυτή η διφασική προσέγγιση επιτρέπει στο BERT να επιτύχει κορυφαία αποτελέσματα σε μια ευρεία γκάμα προτύπων NLP, αποδεικνύοντας την αποτελεσματικότητα της μεταφοράς μάθησης στα γλωσσικά μοντέλα (Google AI Blog).
BERT vs. Παραδοσιακά Μοντέλα NLP: Τι το Διαχωρίζει;
Το BERT (Διεύθυνες Κωδικοποιήσεις από Transformers) αντιπροσωπεύει μια σημαντική αναχώρηση από τα παραδοσιακά μοντέλα Επεξεργασίας Φυσικής Γλώσσας (NLP), κυρίως λόγω της διευθυντικής κατανόησης πλαισίου του και της αρχιτεκτονικής που βασίζεται σε transformers. Τα παραδοσιακά μοντέλα NLP, όπως τα μοντέλα “bag-of-words”, οι μονάδες n-gram και οι πρώιμες αναπαραστάσεις λέξεων όπως το Word2Vec ή το GloVe, συνήθως επεξεργάζονται το κείμενο με μη κατευθυντικό ή ανεξάρτητο από το πλαίσιο τρόπο. Για παράδειγμα, μοντέλα όπως το Word2Vec παράγουν διανύσματα λέξεων βασιζόμενα αποκλειστικά σε τοπικά περιβάλλοντα, και τα ανακυκλούμενα νευρωνικά δίκτυα (RNNs) επεξεργάζονται τις ακολουθίες είτε από αριστερά προς τα δεξιά είτε από δεξιά προς τα αριστερά, περιορίζοντας την ικανότητά τους να καταγράφουν το πλήρες πλαίσιο της πρότασης.
Αντίθετα, το BERT αξιοποιεί μια αρχιτεκτονική transformers που του επιτρέπει να εξετάσει ταυτόχρονα τόσο το αριστερό όσο και το δεξί πλαίσιο για κάθε λέξη σε μια πρόταση. Αυτή η διευθυντική προσέγγιση επιτρέπει στο BERT να παράγει πλουσιότερες, ευαίσθητες στις γεωμορφίες αναπαραστάσεις λέξεων, οι οποίες είναι ιδιαίτερα πλεονεκτικές για εργασίες που απαιτούν λεπτομερή κατανόηση, όπως η ερώτηση απάντησης και η ανάλυση συναισθήματος. Επιπλέον, το BERT είναι προεκπαιδευμένο σε μεγάλες συλλογές κειμένου χρησιμοποιώντας στόχους μοντελοποίησης μάσκας γλώσσας και προγραμματισμού επόμενης πρότασης, επιτρέποντάς του να μάθει βαθιά σημασιολογικά και συντακτικά χαρακτηριστικά πριν τον χοντροκόπημα σε συγκεκριμένες εργασίες.
Εμπειρικά αποτελέσματα έχουν δείξει ότι το BERT επαληθεύει συνεχώς την ανωτερότητά του σε παραδοσιακά μοντέλα σε μια ευρεία γκάμα προτύπων NLP, συμπεριλαμβανομένων των συνόλων δεδομένων GLUE και SQuAD. Η αρχιτεκτονική και η παραδειγματική εκπαίδευση αυτής της πλατφόρμας έχουν θέσει νέα πρότυπα για τη μεταφορά μάθησης στο NLP, επιτρέποντας στους επαγγελματίες να επιτύχουν κορυφαία αποτελέσματα με ελαχιστοποιημένες αλλαγές στη αρχιτεκτονική ειδικών εργασιών. Για περισσότερες λεπτομέρειες, ανατρέξτε στο πρωτότυπο άρθρο από την Google AI Language και την επίσημη αποθήκη του BERT στο GitHub.
Πραγματικές Εφαρμογές: Το BERT στην Αναζήτηση, τα Chatbots και Πέρα από Αύτα
Ο μετασχηματιστικός αντίκτυπος του BERT στην επεξεργασία φυσικής γλώσσας (NLP) είναι πιο προφανής στις πραγματικές του εφαρμογές, ιδιαίτερα σε μηχανές αναζήτησης, chatbots και διάφορους άλλους τομείς. Στην αναζήτηση, το BERT επιτρέπει στα συστήματα να κατανοούν καλύτερα το πλαίσιο και την πρόθεση πίσω από τις ερωτήσεις χρηστών, οδηγώντας σε πιο σχετικά και ακριβή αποτελέσματα. Για παράδειγμα, η Google ενσωμάτωσε το BERT στους αλγόριθμους αναζήτησής της για να βελτιώσει την ερμηνεία των συνομιλητικών ερωτήσεων, ειδικά εκείνων που περιλαμβάνουν προθέσεις και λεπτές διατυπώσεις. Αυτή η πρόοδος επιτρέπει στις μηχανές αναζήτησης να αντιστοιχούν τις ερωτήσεις με το περιεχόμενο με έναν τρόπο που πιο κοντά να απεικονίζει την ανθρώπινη κατανόηση.
Στον τομέα της συνομιλητικής AI, το BERT έχει σημαντικά ενισχύσει την απόδοση των chatbots. Αξιοποιώντας την βαθιά διευθυντική του κατάσταση, τα chatbots μπορούν να δημιουργήσουν πιο συνεκτικές και κατάλληλες απαντήσεις, βελτιώνοντας την ικανοποίηση και την αλληλεπίδραση χρηστών. Εταιρείες όπως η Microsoft έχουν ενσωματώσει το BERT στις πλατφόρμες συνομιλητικής AI τους, διευκολύνοντας τις πιο φυσικές και αποτελεσματικές αλληλεπιδράσεις στην εξυπηρέτηση πελατών και τις εφαρμογές εικονικών βοηθών.
Πέρα από την αναζήτηση και τα chatbots, η αρχιτεκτονική του BERT έχει προσαρμοστεί σε εργασίες όπως η ανάλυση συναισθήματος, η κατηγοριοποίηση εγγράφων και η ερώτηση απάντησης. Η ικανότητά του να προσαρμόζεται σε συγκεκριμένες εργασίες με σχετικά μικρά σύνολα δεδομένων έχει δημοκρατήσει την πρόσβαση σε κορυφαία NLP, επιτρέποντας οργανισμούς όλων των μεγεθών να αναπτύξουν προχωρημένες δυνατότητες κατανόησης γλώσσας. Ως εκ τούτου, το BERT συνεχίζει να προάγει την καινοτομία σε βιομηχανίες, από την υγειονομική περίθαλψη έως τα χρηματοοικονομικά, επιτρέποντας στις μηχανές να επεξεργάζονται και να ερμηνεύουν την ανθρώπινη γλώσσα με απαράμιλλη ακρίβεια και λεπτότητα.
Περιορισμοί και Προκλήσεις: Πού Υστερεί το BERT
Παρά την μετασχηματιστική του επίδραση στην επεξεργασία φυσικής γλώσσας, το BERT παρουσιάζει αρκετούς notable περιορισμούς και προκλήσεις. Ένα βασικό θέμα είναι η υπολογιστική του ένταση; τόσο η προεκπαίδευση όσο και η χοντροκόπημα του BERT απαιτούν σημαντικούς πόρους υπολογιστή, περιορίζοντας την προσβασιμότητά του για οργανισμούς με περιορισμένες υπολογιστικές υποδομές. Το μεγάλο μέγεθος του μοντέλου οδηγεί επίσης σε υψηλή κατανάλωση μνήμης και αργούς χρόνους παρέμβασης, που μπορεί να εμποδίσουν την ανάπτυξη σε πραγματικό χρόνο ή περιορισμένα περιβάλλοντα πόρων (Google AI Blog).
Η αρχιτεκτονική του BERT είναι εγγενώς περιορισμένη σε σταθερές ακολουθίες εισόδου, με συχνά ανώτατο όριο τα 512 tokens. Αυτή η περιορισμένη ύπαρξη θέτει προκλήσεις για εργασίες που περιλαμβάνουν μεγαλύτερα έγγραφα, καθώς χρειάζονται στρατηγικές αποκοπής ή σύνθετης διάσπασης που ενδέχεται να οδηγήσουν σε απώλεια πλαισίου και μείωση απόδοσης (arXiv). Επιπλέον, το BERT είναι προεκπαιδευμένο σε μεγάλες, γενικές συλλογές κειμένων, γεγονός που μπορεί να οδηγήσει σε υποβέλτιστη απόδοση σε τοπικές εργασίες εκτός εάν πραγματοποιηθεί περαιτέρω προσαρμογή.
Μια άλλη πρόκληση είναι η αδυναμία του BERT να εκτελεί λογική σκέψη ή να διαχειρίζεται εργασίες που απαιτούν παγκόσμια γνώση πέρα από αυτά που υπάρχουν στα δεδομένα εκπαίδευσης του. Το μοντέλο είναι επίσης ευαίσθητο σε επιθέσεις που προκαλούν ζημία και μπορεί να παράγει μεροληπτικές ή παραλογιστικές εξόδους, αντανακλώντας τις μεροληπτικές προοπτικές που υπάρχουν στην εκπαίδευση του (Εθνικό Ινστιτούτο Προτύπων και Τεχνολογίας (NIST)). Επιπλέον, η ερμηνευσιμότητα του BERT παραμένει περιορισμένη, καθιστώντας δύσκολη την κατανόηση ή την εξήγηση των προβλέψεών του, γεγονός που είναι σημαντική ανησυχία για εφαρμογές σε ευαίσθητους τομείς όπως η υγειονομική περίθαλψη ή ο νόμος.
Το Μέλλον του BERT: Καινοτομίες, Παραλλαγές και Τι Ακολουθεί
Από την εισαγωγή του, οι Διεύθυνες Κωδικοποιήσεις από Transformers (BERT) έχουν επαναστατήσει την επεξεργασία φυσικής γλώσσας (NLP), αλλά το πεδίο συνεχίζει να εξελίσσεται ταχύτατα. Το μέλλον του BERT διαμορφώνεται από συνεχιζόμενες καινοτομίες, την εμφάνιση πολλών παραλλαγών και την ενσωμάτωση νέων τεχνικών για την αντιμετώπιση των περιορισμών του. Μια κύρια κατεύθυνση είναι η ανάπτυξη πιο αποδοτικών και κλιμακωτών μοντέλων. Για παράδειγμα, μοντέλα όπως το DistilBERT και το TinyBERT προσφέρουν ελαφρύτερες εναλλακτικές που διατηρούν μεγάλο μέρος της απόδοσης του BERT ενώ μειώνουν τις υπολογιστικές απαιτήσεις, καθιστώντας τα κατάλληλα για ανάπτυξη σε edge συσκευές και σε πραγματικούς χρόνους εφαρμογές (Hugging Face).
Μια άλλη σημαντική τάση είναι η προσαρμογή του BERT για πολύγλωσσες και τοπικές εργασίες. Το Πολύγλωσσο BERT (mBERT) και μοντέλα όπως το BioBERT και το SciBERT είναι προσαρμοσμένα για συγκεκριμένες γλώσσες ή επιστημονικούς τομείς, αναδεικνύοντας την ευελιξία της αρχιτεκτονικής του BERT (Google AI Blog). Επιπλέον, η έρευνα εστιάζει στη βελτίωση της ερμηνευσιμότητας και της ανθεκτικότητας του BERT, αντιμετωπίζοντας ανησυχίες σχετικά με τη διαφάνεια του μοντέλου και ευπάθειες σε επιθέσεις.
Κοιτάζοντας μπροστά, η ενσωμάτωση του BERT με άλλες μορφές, όπως η οπτική και η ομιλία, είναι μια υποσχόμενη περιοχή, όπως φαίνεται σε μοντέλα όπως το VisualBERT και το SpeechBERT. Επιπλέον, η άνοδος των μεγάλης κλίμακας προεκπαιδευμένων μοντέλων, όπως το GPT-3 και το T5, έχει εμπνεύσει υβριδικές αρχιτεκτονικές που συνδυάζουν τις δυνάμεις της διευθυντικής κωδικοποίησης του BERT με γεννητικές ικανότητες (Google AI Blog). Καθώς η έρευνα συνεχίζεται, το BERT και οι διάδοχοί του αναμένεται να διαδραματίσουν κεντρικό ρόλο στην προώθηση των ικανοτήτων των συστημάτων AI σε διάφορες εφαρμογές.
Πηγές & Αναφορές
- Google AI Language
- Vaswani et al. (2017)
- Google Research
- Εθνικό Ινστιτούτο Προτύπων και Τεχνολογίας (NIST)
- Hugging Face