Uvnitř BERT: Jak dvoucestné enkodérské reprezentace z Transformátorů redefinují zpracování přirozeného jazyka a pohání další generaci aplikací AI
- Úvod do BERT: Původ a průlomy
- Jak BERT funguje: Věda za dvoucestnými transformátory
- Předtrénink a doladění: Dvoustupňový učební proces BERT
- BERT vs. Tradiční NLP modely: Čím se odlišuje?
- Skutečné aplikace: BERT ve vyhledávání, chatovacích robotech a dalších oblastech
- Omezení a výzvy: Kde BERT selhává
- Budoucnost BERT: Inovace, varianty a co přijde dál
- Zdroje & Odkazy
Úvod do BERT: Původ a průlomy
Dvoucestné enkodérské reprezentace z Transformátorů (BERT) představují významný milník v evoluci zpracování přirozeného jazyka (NLP). Představena výzkumníky z Google AI Language v roce 2018, BERT zásadně změnila způsob, jakým stroje chápou jazyk, tím, že vychází z výhod hlubokých dvoucestných transformátorů. Na rozdíl od předchozích modelů, které zpracovávaly text buď zleva doprava, nebo zprava doleva, architektura BERT umožňuje zohlednit kontext slova tím, že současně zohledňuje jeho leva a pravá okolí. Tento dvoucestný přístup umožňuje nuancovanější porozumění jazyku, zachycující jemné vztahy a významy, které jednocestné modely často přehlížejí.
Původ BERT je zakotven v architektuře transformátorů, kterou poprvé představil Vaswani et al. (2017), a která se spoléhá na mechanismy sebevědomí k paralelnímu zpracování vstupních sekvencí. Předtrénováním na obrovských korpusech, jako je Wikipedia a BooksCorpus, se BERT učí obecné jazykové reprezentace, které lze jemně doladit pro široké spektrum úloh, včetně odpovídání na otázky, analýzy sentimentu a rozpoznávání pojmenovaných entit. Uvolnění BERT nastavilo nové standardy napříč více NLP úlohami, čímž překonalo předchozí špičkové modely a inspirovalo vlnu výzkumu v architekturách na bázi transformátorů.
Průlomy, kterých BERT dosáhla, nejenže pokročily akademický výzkum, ale vedly také k praktickým zlepšením v komerčních aplikacích, jako jsou vyhledávače a virtuální asistenti. Její open-source uvolnění demokratizovalo přístup k mocným jazykovým modelům, podporujícím inovace a spolupráci v celé komunitě NLP.
Jak BERT funguje: Věda za dvoucestnými transformátory
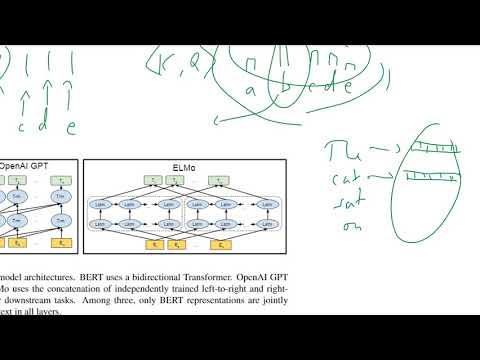
Hlavní inovace BERT spočívá v používání dvoucestných transformátorů, které zásadně mění způsob, jakým jazykové modely rozumí kontextu. Na rozdíl od tradičních modelů, které zpracovávají text buď zleva doprava, nebo zprava doleva, BERT využívá architekturu transformátorů k analýze všech slov ve větě současně, přičemž zohledňuje jak předchozí, tak následující slova. Tento dvoucestný přístup umožňuje BERT zachytit nuancované vztahy a závislosti v jazyce, což vede k hlubšímu porozumění významu a kontextu.
Věda, která stojí za dvoucestností BERT, spočívá v jejích předtréninkových úlohách: maskované modelování jazyka (MLM) a predikce následující věty (NSP). V MLM jsou náhodně vybraná slova ve větě maskována a model se učí předpovídat tyto maskované tokeny tím, že zohledňuje celý kontext na obou stranách. To kontrastuje s předchozími modely, které mohly používat pouze částečný kontext, což omezovalo jejich porozumění. NSP, na druhou stranu, školí BERT, aby pochopil vztah mezi páry vět, což dále zlepšuje její chápání kontextu a koherence.
Architektura BERT je založena na enkodéru transformátoru, který využívá mechanismy sebevědomí k hodnocení důležitosti každého slova v poměru k ostatním ve vstupu. To umožňuje BERT modelovat složité jazykové jevy, jako je polysemie a dlouhé závislosti. Výsledkem je model, který dosahuje špičkového výkonu v širokém spektru úloh zpracování přirozeného jazyka, včetně odpovídání na otázky a analýzy sentimentu. Pro podrobný technický přehled se podívejte na původní článek od Google AI Language a oficiální dokumentaci od Google Research.
Předtrénink a doladění: Dvoustupňový učební proces BERT
Výjimečný výkon BERT v úlohách zpracování přirozeného jazyka je z velké části přičítán jejímu inovativnímu dvoustupňovému učebnímu procesu: předtrénink a doladění. Během fáze předtréninku je BERT vystavena obrovskému množství neoznačeného textu, učí se obecným jazykovým reprezentacím prostřednictvím dvou úloh se sebekontrolou: maskovaného modelování jazyka (MLM) a predikce následující věty (NSP). V MLM jsou náhodně vybraná slova ve větě maskována a model se učí předpovídat tyto maskované tokeny na základě jejich kontextu, což umožňuje hluboké dvoucestné porozumění. NSP, na druhou stranu, školí BERT, aby určila, zda jedna věta logicky následuje druhou, což je klíčové pro úlohy zahrnující vztahy mezi větami (Google Research).
Po předtréninku BERT prochází dolaďováním na specifické úlohy, jako je odpovídání na otázky, analýza sentimentu nebo rozpoznávání pojmenovaných entit. V této fázi se předtrénovaný model dále trénuje na menším, označeném datasetu přizpůsobeném cílové úloze. Architektura zůstává z velké části nezměněna, ale specifické vrstvy pro úlohu (např. klasifikační hlavy) jsou přidávány podle potřeby. Dolaďování obvykle vyžaduje pouze několik epoch a relativně málo dat, protože model už během předtréninku získal robustní porozumění jazyku. Tento dvoustupňový přístup umožňuje BERT dosáhnout špičkových výsledků napříč širokým spektrem NLP benchmarků, což dokazuje účinnost transferového učení v jazykových modelech (Google AI Blog).
BERT vs. Tradiční NLP modely: Čím se odlišuje?
BERT (Dvoucestné enkodérské reprezentace z transformátorů) představuje významný odklon od tradičních modelů zpracování přirozeného jazyka (NLP), především díky svému dvoucestnému chápání kontextu a architektuře založené na transformátorech. Tradiční modely NLP, jako jsou modely bag-of-words, n-gram a dřívější vektory slov jako Word2Vec nebo GloVe, obvykle zpracovávají text jednocestně nebo v nezávislém kontextu. Například modely jako Word2Vec generují vektory slov pouze na základě lokálních kontextových oken, a rekurentní neuronové sítě (RNN) zpracovávají sekvence buď zleva doprava, nebo zprava doleva, což omezuje jejich schopnost zachytit plný kontext vět.
Naopak, BERT využívá architekturu transformátorů, která mu umožňuje zohlednit jak levý, tak pravý kontext současně pro každé slovo ve větě. Tento dvoucestný přístup umožňuje BERT generovat bohatší, kontextově citlivé reprezentace slov, což je zvlášť výhodné pro úlohy vyžadující nuancované porozumění, jako je odpovídání na otázky a analýza sentimentu. Kromě toho je BERT předtrénován na velkých korpusech pomocí cílů maskovaného modelování jazyka a predikce následující věty, což mu umožňuje naučit se hluboké sémantické a syntaktické rysy před doladěním na specifické downstream úkoly.
Empirické výsledky ukázaly, že BERT konzistentně překonává tradiční modely napříč širokým spektrem NLP benchmarků, včetně datasetů GLUE a SQuAD. Její architektura a tréninkový paradigmata nastavily nové standardy pro transferové učení v NLP, což umožňuje praktikům dosahovat špičkových výsledků s minimálními úpravami architektury pro konkrétní úkoly. Pro více informací se podívejte na původní článek od Google AI Language a oficiální repozitář BERT na GitHubu.
Skutečné aplikace: BERT ve vyhledávání, chatovacích robotech a dalších oblastech
Transformativní dopad BERT na zpracování přirozeného jazyka (NLP) je nejvíce zřejmý v jejích skutečných aplikacích, zejména ve vyhledávačích, chatovacích robotech a v různých dalších oblastech. V oblasti vyhledávání BERT umožňuje systémům lépe porozumět kontextu a úmyslu za uživatelskými dotazy, což vede k relevantnějším a přesnějším výsledkům. Například Google integroval BERT do svých vyhledávacích algoritmů, aby zlepšil interpretaci konverzačních dotazů, zejména těch, které obsahují předložky a nuance frazování. Tento pokrok umožňuje vyhledávačům lépe shodovat dotazy s obsahem způsobem, který blíže odpovídá lidskému porozumění.
Ve sféře konverzační AI BERT významně vylepšil výkon chatovacích robotů. využíváním svého hlubokého dvoucestného kontextu mohou chatboti generovat koherentnější a kontextově vhodnější odpovědi, což zvyšuje spokojenost a zapojení uživatelů. Společnosti jako Microsoft začleňují BERT do svých platforem konverzační AI, což umožňuje přirozenější a účinnější interakce v zákaznických službách a aplikacích virtuálních asistentů.
Mimo vyhledávání a chatovací roboty byla architektura BERT přizpůsobena pro úkoly, jako je analýza sentimentu, klasifikace dokumentů a odpovídání na otázky. Její schopnost být doladěna pro specifické úkoly s relativně malými datovými sadami demokratizovala přístup k špičkovému NLP, což umožnilo organizacím všech velikostí nasadit pokročilé jazykové porozumění. V důsledku toho BERT i nadále pohání inovace napříč průmyslovými odvětvími, od zdravotní péče po finance, tím, že umožňuje strojům zpracovávat a interpretovat lidský jazyk s bezprecedentní přesností a nuancí.
Omezení a výzvy: Kde BERT selhává
I přes svůj transformativní dopad na zpracování přirozeného jazyka vykazuje BERT několik významných omezení a výzev. Hlavním problémem je její výpočetní náročnost; jak předtrénink, tak doladění BERT vyžadují značné hardwarové zdroje, což ji činí méně přístupnou pro organizace s omezenou výpočetní infrastruktuře. Velikost modelu také vede k vysoké spotřebě paměti a pomalejšímu času inferencí, což může bránit nasazení v reálném čase nebo v prostředích s omezenými zdroji (Google AI Blog).
Architektura BERT je částečně omezena na vstupní sekvence s pevnou délkou, obvykle omezené na 512 tokenů. Toto omezení představuje výzvy pro úlohy zahrnující delší dokumenty, jelikož je nezbytné truncování nebo složité dělení strategií, což může vést ke ztrátě kontextu a zhoršení výkonu (arXiv). Kromě toho je BERT předtrénován na velkých korpusech obecného charakteru, což může znamenat suboptimální výkon při úlohách specifických pro obor, pokud nejsou provedeny dodatečné úpravy oboru.
Další výzvou je neschopnost BERT vykonávat úsudek nebo řešit úkoly vyžadující světové znalosti, které přesahují to, co je obsaženo v jejích tréninkových datech. Model je také náchylný k útokům a může produkovat zaujaté nebo nesmyslné výstupy, které odrážejí zaujatosti přítomné v jejích tréninkových datech (Národní úřad pro normy a technologie (NIST)). Kromě toho zůstává interpretovatelnost BERT omezená, což ztěžuje pochopení nebo vysvětlení jejích predikcí, což je významná obava pro aplikace v citlivých oblastech, jako je zdravotní péče nebo právo.
Budoucnost BERT: Inovace, varianty a co přijde dál
Od svého zavedení Dvoucestné enkodérské reprezentace z transformátorů (BERT) revolucionalizovaly zpracování přirozeného jazyka (NLP), ale oblast se nadále rychle vyvíjí. Budoucnost BERT je ovlivněna probíhajícími inovacemi, vznikem mnoha variant a integrací nových technik na řešení jejích omezení. Jedním z hlavních směrů je vývoj efektivnějších a škálovatelných modelů. Například modely jako DistilBERT a TinyBERT nabízejí lehké alternativy, které si udržují velkou část výkonu BERT, přičemž snižují výpočetní požadavky, což je činí vhodnými pro nasazení na okrajových zařízeních a v aplikacích v reálném čase (Hugging Face).
Dalším významným trendem je přizpůsobení BERT pro vícejazyčné a specifické úkoly. Vícejazyčný BERT (mBERT) a modely jako BioBERT a SciBERT jsou přizpůsobeny pro specifické jazyky nebo vědecké oblasti, což ukazuje flexibilitu architektury BERT (Google AI Blog). Kromě toho je výzkum zaměřen na zlepšení interpretovatelnosti a robustness BERT, čímž se řeší obavy ohledně transparentnosti modelu a zranitelnosti vůči útokům.
Díváme-li se dopředu, integrace BERT s jinými modality, jako je vidění a řeč, představuje slibnou oblast, o čemž svědčí modely jako VisualBERT a SpeechBERT. Kromě toho vzestup velkých předtrénovaných modelů, jako je GPT-3 a T5, inspiroval hybridní architektury, které kombinují sílu dvoucestného kódování BERT generativními schopnostmi (Google AI Blog). Jak výzkum pokračuje, očekává se, že BERT a její nástupci budou hrát klíčovou roli při zlepšování schopností systémů AI napříč různými aplikacemi.
Zdroje & Odkazy
- Google AI Language
- Vaswani et al. (2017)
- Google Research
- Národní úřad pro normy a technologie (NIST)
- Hugging Face