داخل BERT: كيف تعيد تمثيلات المحولات ثنائية الاتجاه تعريف معالجة اللغة الطبيعية وتدعم الجيل القادم من تطبيقات الذكاء الاصطناعي
- مقدمة عن BERT: الأصول والإنجازات
- كيف يعمل BERT: العلم وراء المحولات ثنائية الاتجاه
- التدريب المسبق والتعديل الدقيق: عملية التعلم ذات المرحلتين لـ BERT
- BERT مقابل نماذج معالجة اللغة الطبيعية التقليدية: ما الذي يميزه؟
- التطبيقات العملية: BERT في البحث، والدردشة، وما وراء ذلك
- القيود والتحديات: أين يقصر BERT؟
- مستقبل BERT: الابتكارات، المتغيرات، وما هو التالي
- المصادر والمراجع
مقدمة عن BERT: الأصول والإنجازات
تمثل تمثيلات المحولات ثنائية الاتجاه (BERT) علامة فارقة مهمة في تطور معالجة اللغة الطبيعية (NLP). تم تقديم BERT من قبل الباحثين في Google AI Language في عام 2018، وقد غير بشكل جذري كيفية فهم الآلات للغة من خلال الاستفادة من قوة المحولات ثنائية الاتجاه العميقة. على عكس النماذج السابقة التي عالجت النص إما من اليسار إلى اليمين أو من اليمين إلى اليسار، فإن بنية BERT تجعلها قادرة على اعتبار السياق الكامل للكلمة من خلال النظر إلى كل من محيطها الأيسر والأيمن في آن واحد. تسمح هذه الطريقة ثنائية الاتجاه بفهم أكثر دقة للغة، حيث تلتقط العلاقات والمعاني الدقيقة التي تفوتها النماذج الاتجاهية الأحادية.
تعود أصول BERT إلى بنية المحول، التي قدمها Vaswani et al. (2017)، والتي تعتمد على آليات الانتباه الذاتي لمعالجة تسلسل المدخلات بشكل متوازي. من خلال التدريب المسبق على مجموعات ضخمة مثل ويكيبيديا وBooksCorpus، يتعلم BERT تمثيلات لغة عامة يمكن ضبطها بشكل دقيق لمجموعة واسعة من المهام اللاحقة، بما في ذلك الإجابة على الأسئلة، وتحليل المشاعر، والتعرف على الكيانات المسماة. أدت إطلاق BERT إلى وضع معايير جديدة عبر مهام معالجة اللغة الطبيعية المتعددة، متخطية النماذج السابقة الرائدة في مجالها، وألهمت موجة من الأبحاث حول الهياكل المعتمدة على المحولات.
لم تؤدي الإنجازات التي حققتها BERT إلى تقدم البحث الأكاديمي فحسب، بل أدت أيضًا إلى تحسينات عملية في التطبيقات التجارية، مثل محركات البحث والمساعدين الافتراضيين. إن إصدارها كمصدر مفتوح قد ديمقراطى الوصول إلى نماذج اللغة القوية، مما يعزز الابتكار والتعاون في جميع أنحاء مجتمع معالجة اللغة الطبيعية.
كيف يعمل BERT: العلم وراء المحولات ثنائية الاتجاه
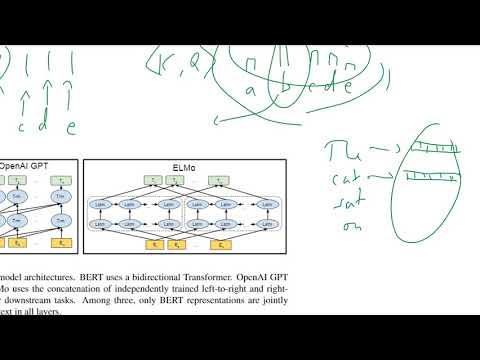
تكمن الابتكارات الأساسية في BERT في استخدامها للمحولات ثنائية الاتجاه، والتي تغير بشكل جذري كيفية فهم نماذج اللغة للسياق. على عكس النماذج التقليدية التي تعالج النص من اليسار إلى اليمين أو من اليمين إلى اليسار، يستفيد BERT من بنية المحولات لتحليل جميع الكلمات في جملة في آن واحد، مع الأخذ في الاعتبار كل من الكلمات السابقة واللاحقة. تتيح هذه الطريقة ثنائية الاتجاه لـ BERT التقاط العلاقات الدقيقة والاعتماديات داخل اللغة، مما يؤدي إلى فهم أعمق للمعنى والسياق.
العلم وراء الاتجاه الثنائي في BERT متجذر في مهام التدريب المسبق الخاصة به: نمذجة اللغة المmasked (MLM) وتوقع الجملة التالية (NSP). في MLM، يتم إخفاء كلمات عشوائية في جملة، ويتعلم النموذج التنبؤ بهذه الرموز المخفية من خلال النظر في السياق الكامل على كلا الجانبين. يتعارض ذلك مع النماذج السابقة، التي كانت قادرة فقط على استخدام سياق جزئي، مما يحد من فهمها. من ناحية أخرى، تدرب NSP BERT على فهم العلاقة بين أزواج الجمل، مما يعزز من فهمه للسياق والترابط.
تعتمد بنية BERT على محول الترميز، الذي يستخدم آليات الانتباه الذاتي لقياس أهمية كل كلمة بالنسبة إلى الكلمات الأخرى في المدخلات. يتيح ذلك لـ BERT نمذجة الظواهر اللغوية المعقدة مثل التعدد الدلالي والاعتماديات بعيدة المدى. والنتيجة هي نموذج يحقق أداءً رائدًا في مجموعة واسعة من مهام معالجة اللغة الطبيعية، بما في ذلك الإجابة على الأسئلة وتحليل المشاعر. للحصول على نظرة فنية مفصلة، راجع الورقة الأصلية من قبل Google AI Language والوثائق الرسمية من Google Research.
التدريب المسبق والتعديل الدقيق: عملية التعلم ذات المرحلتين لـ BERT
ترجع الأداء الملحوظ لـ BERT في مهام معالجة اللغة الطبيعية إلى عملية التعلم ذات المرحلتين المبتكرة: التدريب المسبق والتعديل الدقيق. خلال مرحلة التدريب المسبق، يتعرض BERT لكميات هائلة من النصوص غير المصنفة، ويتعلم تمثيلات اللغة العامة من خلال مهمتين من التعلم الذاتي: نمذجة اللغة المmasked (MLM) وتوقع الجملة التالية (NSP). في MLM، يتم إخفاء كلمات عشوائية في جملة، ويتعلم النموذج التنبؤ بهذه الرموز المخفية استنادًا إلى سياقها، مما يتيح فهمًا ثنائي الاتجاه عميقًا. من ناحية أخرى، يدرب NSP BERT على تحديد ما إذا كانت جملة واحدة تتبع منطقًا جملة أخرى، وهو أمر حاسم للمهام التي تتضمن علاقات الجمل (Google Research).
بعد التدريب المسبق، يخضع BERT لـ تعديل دقيق على مهام محددة لاحقة مثل الإجابة على الأسئلة، تحليل المشاعر، أو التعرف على الكيانات المسماة. في هذه المرحلة، يتم تدريب النموذج المدرب مسبقًا بشكل إضافي على مجموعة بيانات أصغر ومصنفة مصممة للمهمة المستهدفة. تبقى البنية بشكل عام دون تغيير، ولكن تضاف طبقات خاصة بالمهمة (مثل رؤوس التصنيف) حسب الحاجة. يتطلب التعديل الدقيق عادةً بضع دورات وبيانات قليلة نسبيًا، حيث أن النموذج قد حصل بالفعل على فهم قوي للغة خلال التدريب المسبق. تتيح هذه الطريقة الثنائية BERT لتحقيق نتائج رائدة عبر مجموعة واسعة من المعايير المستخدمة في معالجة اللغة الطبيعية، مما يظهر فعالية التعلم الانتقالي في نماذج اللغة (Google AI Blog).
BERT مقابل نماذج معالجة اللغة الطبيعية التقليدية: ما الذي يميزه؟
يمثل BERT (تمثيلات المحولات ثنائية الاتجاه) انحرافًا كبيرًا عن نماذج معالجة اللغة الطبيعية التقليدية، ويرجع ذلك أساسًا إلى فهمه للسياق ثنائي الاتجاه وبنيته المعتمدة على المحولات. نماذج معالجة اللغة الطبيعية التقليدية، مثل نموذج كيس الكلمات، ونماذج n-gram، و تمثيلات الكلمات السابقة مثل Word2Vec أو GloVe، عادةً ما تعالج النص بطريقة أحادية الاتجاه أو مستقلة عن السياق. على سبيل المثال، تولد نماذج مثل Word2Vec متجهات الكلمات بناءً فقط على نوافذ السياق المحلية، وتعالج الشبكات العصبية التكرارية (RNNs) التسلسلات إما من اليسار إلى اليمين أو من اليمين إلى اليسار، مما يحد من قدرتها على التقاط السياق الكامل للجملة.
بالمقارنة، يستفيد BERT من بنية المحولات التي تمكنه من النظر إلى السياق الأيسر والأيمن في آن واحد لكل كلمة في الجملة. تتيح هذه الطريقة ثنائية الاتجاه لـ BERT توليد تمثيلات أغنى للكلمات تعتمد على السياق، مما يعد ميزة كبيرة للمهام التي تتطلب فهمًا دقيقًا، مثل الإجابة على الأسئلة وتحليل المشاعر. بالإضافة إلى ذلك، يتم تدريب BERT مسبقًا على مجموعات ضخمة باستخدام نمذجة اللغة المmasked وأهداف توقع الجملة التالية، مما يسمح له بتعلم ميزات دلالية ونحوية عميقة قبل التعديل الدقيق على مهام لاحقة محددة.
أظهرت النتائج التجريبية أن BERT يتفوق باستمرار على النماذج التقليدية عبر مجموعة واسعة من معايير معالجة اللغة الطبيعية، بما في ذلك مجموعات بيانات GLUE و SQuAD. لقد وضعت بنية BERT ونموذج تدريبه معايير جديدة للتعلم الانتقالي في معالجة اللغة الطبيعية، مما يمكّن المختصين من تحقيق نتائج ريادية مع تعديلات قليلة على بنية المهام المحددة. لمزيد من التفاصيل، راجع الورقة الأصلية من Google AI Language ومستودع BERT GitHub الرسمي.
التطبيقات العملية: BERT في البحث، والدردشة، وما وراء ذلك
يتجلى التأثير التحويلي لـ BERT على معالجة اللغة الطبيعية بشكل أكبر في تطبيقاته العملية، خصوصًا في محركات البحث والدردشة ومجموعة متنوعة من المجالات الأخرى. في البحث، يمكّن BERT الأنظمة من فهم أفضل للسياق والنوايا خلف استفسارات المستخدمين، مما يؤدي إلى نتائج أكثر دقة وملاءمة. على سبيل المثال، قام Google بدمج BERT في خوارزميات البحث الخاصة به لتحسين تفسير الاستفسارات المحادثية، خاصة تلك التي تتضمن حروف الجر وصياغة دقيقة. يسمح هذا التقدم لمحركات البحث بمطابقة الاستفسارات مع المحتوى بطريقة تعكس فهم البشر بشكل أقرب.
في مجال الذكاء الاصطناعي المحادثي، قامت BERT بتحسين أداء الدردشة بشكل كبير. من خلال الاستفادة من سياقها الثنائي العميق، يمكن للدردشة توليد ردود أكثر تماسكًا وملاءمة من الناحية السياقية، مما يحسن من رضا المستخدمين وتفاعلهم. قامت شركات مثل Microsoft بدمج BERT في منصاتها للذكاء الاصطناعي المحادثي، مما يتيح تفاعلات أكثر طبيعية وفعالية في خدمة العملاء وتطبيقات المساعدين الافتراضيين.
بعيدًا عن البحث والدردشة، تم تعديل بنية BERT لمهام مثل تحليل المشاعر، وتصنيف الوثائق، والإجابة على الأسئلة. تتيح قدرته على التعديل الدقيق لمهام محددة باستخدام مجموعات بيانات صغيرة نسبيًا للجميع الوصول إلى معالجة اللغة الطبيعية المتقدمة، مما يتيح للمنظمات من جميع الأحجام تنفيذ قدرات فهم اللغة المتقدمة. نتيجة لذلك، تستمر BERT في دفع الابتكار عبر الصناعات، من الرعاية الصحية إلى المالية، من خلال تمكين الآلات من معالجة وتفسير اللغة البشرية بدقة ونقطة غير مسبوقين.
القيود والتحديات: أين يقصر BERT؟
على الرغم من تأثيره التحويلي على معالجة اللغة الطبيعية، تظهر BERT العديد من القيود والتحديات الملحوظة. إحدى القضايا الرئيسية هي كثافتها الحاسوبية؛ يتطلب كل من التدريب المسبق والتعديل الدقيق لـ BERT موارد هاردوير كبيرة، مما يجعله أقل وصولًا للمنظمات التي تملك بنية تحتية حاسوبية محدودة. كما أن حجم النموذج الكبير يؤدي إلى استهلاك عالي للذاكرة وأوقات استنتاج أبطأ، مما قد يعوق نشره في بيئات الوقت الحقيقي أو التي تقتصر على الموارد (Google AI Blog).
بنية BERT محدودة بطبيعتها على تسلسلات المدخلات الثابتة الطول، والتي عادةً ما تكون محدودة بـ 512 رمز. تطرح هذه القيود تحديات للمهام التي تتضمن مستندات أطول، حيث تتطلب الاستقطاعات أو استراتيجيات تقسيم معقدة، مما يؤدي إلى فقدان السياق وتدهور الأداء (arXiv). بالإضافة إلى ذلك، يتم تدريب BERT مسبقًا على مجموعات عامة كبيرة، مما قد يؤدي إلى أداء غير مثالي في المهام المحددة بالمجالات ما لم يتم إجراء تكييف إضافي مع المجال.
تحدي آخر هو عدم قدرة BERT على إجراء الاستدلال أو التعامل مع المهام التي تتطلب معرفة بالمعلومات التي تتجاوز ما هو موجود في بيانات تدريبه. النموذج أيضًا عرضة للهجمات العدائية ويمكن أن ينتج مخرجات متحيزة أو غير منطقية، تعكس التحيزات الموجودة في بيانات تدريبه (المعهد الوطني للمعايير والتكنولوجيا (NIST)). علاوة على ذلك، تبقى إمكانية تفسير BERT محدودة، مما يجعل من الصعب فهم أو تفسير تنبؤاته، وهو ما يعتبر مصدر قلق كبير للتطبيقات في مجالات حساسة مثل الرعاية الصحية أو القانون.
مستقبل BERT: الابتكارات، المتغيرات، وما هو التالي
منذ تقديمه، أحدثت تمثيلات المحولات ثنائية الاتجاه (BERT) ثورة في معالجة اللغة الطبيعية (NLP)، لكن المجال لا يزال يتطور بسرعة. يتم تشكيل مستقبل BERT من خلال الابتكارات المستمرة، وظهور العديد من المتغيرات، ودمج تقنيات جديدة لمعالجة قيوده. أحد الاتجاهات الكبيرة هو تطوير نماذج أكثر كفاءة وقابلية للتوسع. على سبيل المثال، تقدم نماذج مثل DistilBERT وTinyBERT بدائل خفيفة الوزن تحتفظ بالكثير من أداء BERT مع تقليل متطلبات الحساب، مما يجعلها مناسبة للنشر على الأجهزة المحمولة وفي تطبيقات الوقت الحقيقي (Hugging Face).
اتجاه آخر هام هو تكييف BERT لمهام متعددة اللغات ومحددة المجال. تم تصميم BERT متعدد اللغات (mBERT) ونماذج مثل BioBERT وSciBERT لتلبية احتياجات لغات أو مجالات علمية معينة، مما يظهر مرونة بنية BERT (Google AI Blog). بالإضافة إلى ذلك، تتركز الأبحاث على تحسين قدرة تفسير BERT ومرونته، لمعالجة المخاوف المتعلقة بشفافية النموذج وضعف الهجمات العدائية.
وبالنظر إلى المستقبل، فإن دمج BERT مع وسائط أخرى، مثل الرؤية والكلام، يمثل منطقة واعدة، كما نرى في نماذج مثل VisualBERT وSpeechBERT. علاوة على ذلك، ألهم ظهور نماذج كبيرة تم تدريبها مسبقًا، مثل GPT-3 وT5، بناء هياكل هجينة تجمع بين ميزات ترميز BERT ثنائية الاتجاه وقدرات التوليد (Google AI Blog). مع استمرار الأبحاث، من المتوقع أن تلعب BERT وورثتها دورًا مركزيًا في تعزيز قدرات نظم الذكاء الاصطناعي عبر تطبيقات متنوعة.
المصادر والمراجع
- Google AI Language
- Vaswani et al. (2017)
- Google Research
- المعهد الوطني للمعايير والتكنولوجيا (NIST)
- Hugging Face