Inuti BERT: Hur Bidirectional Encoder Representations från Transformers Omdefinierar Naturlig Språkbehandling och Drivkrafter för Nästa Generations AI-applikationer
- Introduktion till BERT: Ursprung och Genombrott
- Hur BERT Fungerar: Vetenskapen bakom Bidirektionella Transformers
- För-träning och Finjustering: BERT:s Tvåstegs Lärandeprocess
- BERT vs. Traditionella NLP-modeller: Vad Skiljer Det Åt?
- Verkliga Tillämpningar: BERT i Sökning, Chatbots och Mer
- Begränsningar och Utmaningar: Där BERT Faller Kort
- BERTs Framtid: Innovationer, Varianter och Vad som Kommer Näst
- Källor & Referenser
Introduktion till BERT: Ursprung och Genombrott
Bidirectional Encoder Representations från Transformers (BERT) representerar en betydande milstolpe i utvecklingen av naturlig språkbehandling (NLP). Introducerad av forskare vid Google AI Language år 2018, förändrade BERT grundläggande hur maskiner förstår språk genom att utnyttja kraften hos djupa bidirektionella transformers. Till skillnad från tidigare modeller som bearbetade text antingen från vänster till höger eller höger till vänster, möjliggör BERT:s arkitektur att den kan betrakta hela kontexten av ett ord genom att titta på både dess vänstra och högra omgivningar samtidigt. Denna bidirektionella metod möjliggör en mer nyanserad förståelse av språket, vilket fångar subtila relationer och betydelser som unidirektionella modeller ofta missar.
BERT:s ursprung är rotad i transformerarkitekturen, först introducerad av Vaswani et al. (2017), som förlitar sig på självuppmärksamhetsmekanismer för att bearbeta inmatningssekvenser parallellt. Genom att förträna på massiva korpusar som Wikipedia och BooksCorpus lär sig BERT allmänna språkrepresentationer som kan finjusteras för en bred uppsättning av nedströmsuppgifter, inklusive frågesvar, känsloanalys och erkännande av namngivna enheter. Utgivningen av BERT satte nya referenspunkter inom flera NLP-uppgifter, överträffade tidigare modeller av högsta kvalitet och inspirerade en våg av forskning kring transformerbaserade arkitekturer.
De genombrott som uppnåddes av BERT har inte bara främjat akademisk forskning utan också lett till praktiska förbättringar inom kommersiella tillämpningar, som sökmotorer och virtuella assistenter. Dess öppen källkod har demokratiserat tillgången till kraftfulla språkmodeller, vilket främjar innovation och samarbete inom NLP-gemenskapen.
Hur BERT Fungerar: Vetenskapen bakom Bidirektionella Transformers
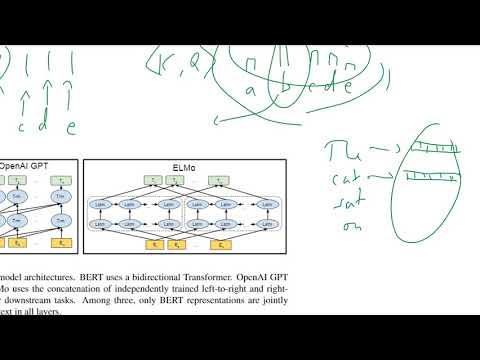
BERT:s kärninvention ligger i dess användning av bidirektionella transformers, som förändrar hur språkmodeller förstår kontext. Till skillnad från traditionella modeller som bearbetar text antingen från vänster till höger eller höger till vänster, utnyttjar BERT en transformerarkitektur för att analysera alla ord i en mening samtidigt, med tanke på både föregående och efterföljande ord. Denna bidirektionella metod möjliggör att BERT fångar nyanserade relationer och beroenden inom språket, vilket leder till en djupare förståelse av betydelse och kontext.
Vetenskapen bakom BERT:s bidirektionalitet är rotad i dess förträningsuppgifter: Maskerad Språklig Modellering (MLM) och Nästa Mening Förutsägning (NSP). I MLM maskeras slumpmässiga ord i en mening, och modellen lär sig att förutsäga dessa maskerade token genom att beakta hela kontexten på båda sidor. Detta står i kontrast till tidigare modeller, som bara kunde använda delvis kontext, vilket begränsade deras förståelse. NSP å sin sida tränar BERT att förstå relationen mellan par av meningar, vilket ytterligare förbättrar dess grepp om kontext och koherens.
BERT:s arkitektur baseras på transformer-enkodern, som använder självuppmärksamhetsmekanismer för att väga vikten av varje ord relativt andra i inmatningen. Detta gör att BERT kan modellera komplexa språkliga fenomen som polysemi och långdistansberoenden. Resultatet är en modell som uppnår prestanda i toppklass inom en bred rad av uppgifter inom naturlig språkbehandling, inklusive frågesvar och känsloanalys. För en detaljerad teknisk översikt, se det ursprungliga dokumentet av Google AI Language och den officiella dokumentationen från Google Research.
För-träning och Finjustering: BERT:s Tvåstegs Lärandeprocess
BERT:s anmärkningsvärda prestanda inom uppgifter för naturlig språkbehandling tillskrivs i stor utsträckning dess innovativa tvåstegs lärandeprocess: för-träning och finjustering. Under för-träningsfasen utsätts BERT för enorma mängder oidentifierad text, lär sig allmänna språkrepresentationer genom två självövervakade uppgifter: Maskerad Språklig Modellering (MLM) och Nästa Mening Förutsägning (NSP). I MLM maskeras slumpmässiga ord i en mening, och modellen lär sig att förutsäga dessa maskerade token baserat på deras kontext, vilket möjliggör djup bidirektionell förståelse. NSP å sin sida tränar BERT att avgöra om en mening logiskt följer en annan, vilket är avgörande för uppgifter som involverar meningars relationer (Google Research).
Efter för-träning genomgår BERT finjustering på specifika nedströmsuppgifter som frågesvar, känsloanalys eller erkännande av namngivna enheter. I detta stadium tränas den förtränade modellen ytterligare på en mindre, märkt datamängd anpassad för den specifika uppgiften. Arkitekturen förblir i stort sett oförändrad, men uppgiftspecifika lager (t.ex. klassificeringshuvuden) läggs till efter behov. Finjustering kräver vanligtvis bara några epoker och relativt lite data, eftersom modellen redan har förvärvat en robust förståelse av språket under för-träning. Denna tvåstegsmetod gör att BERT kan uppnå resultat i toppklass över en bred rad av NLP-referenser, vilket visar effektiviteten av överföringsinlärning i språkmodeller (Google AI Blog).
BERT vs. Traditionella NLP-modeller: Vad Skiljer Det Åt?
BERT (Bidirectional Encoder Representations från Transformers) representerar ett betydande avsteg från traditionella modeller för naturlig språkbehandling (NLP), främst på grund av dess bidirektionella kontextförståelse och transformerbaserade arkitektur. Traditionella NLP-modeller, såsom bag-of-words, n-gram-modeller och tidigare ordinbäddningar som Word2Vec eller GloVe, bearbetar vanligtvis text på ett unidirektionellt eller kontextoberoende sätt. Till exempel genererar modeller som Word2Vec ordvektorer baserat enbart på lokala kontextfönster, och återkommande neurala nätverk (RNN) bearbetar sekvenser antingen från vänster till höger eller höger till vänster, vilket begränsar deras förmåga att fånga hela meningens kontext.
I kontrast utnyttjar BERT en transformerarkitektur som gör att den kan beakta både vänster och höger kontext samtidigt för varje ord i en mening. Denna bidirektionella metod gör att BERT kan generera rikare, kontextkänsliga representationer av ord, vilket är särskilt fördelaktigt för uppgifter som kräver nyanserad förståelse, som frågesvar och känsloanalys. Dessutom är BERT förtränad på stora korpusar med maskerad språklig modellering och nästa meningens förutsägelser, vilket gör att den kan lära sig djupa semantiska och syntaktiska funktioner innan finjustering på specifika nedströmsuppgifter.
Empiriska resultat har visat att BERT konsekvent överträffar traditionella modeller över en bred rad av NLP-referenser, inklusive GLUE- och SQuAD-datamängderna. Dess arkitektur och träningsparadigm har satt nya standarder för överföringsinlärning inom NLP, vilket gör att praktiker kan uppnå resultat i toppklass med minimala uppgiftspecifika arkitekturmodifieringar. För mer detaljer, se det ursprungliga dokumentet av Google AI Language och den officiella BERT GitHub-repositoriet.
Verkliga Tillämpningar: BERT i Sökning, Chatbots och Mer
BERT:s transformerande påverkan på naturlig språkbehandling (NLP) är mest uppenbar i dess verkliga tillämpningar, särskilt inom sökmotorer, chatbots och en mängd andra områden. Inom sökningen möjliggör BERT för system att bättre förstå kontexten och avsikten bakom användarfrågor, vilket leder till mer relevanta och exakta resultat. Till exempel integrerade Google BERT i sina sökalgoritmer för att förbättra tolkningen av konverserande frågor, särskilt de som involverar prepositioner och nyanserad formulering. Denna framsteg gör att sökmotorer kan matcha frågor med innehåll på ett sätt som mer nära speglar mänsklig förståelse.
Inom området konverserande AI har BERT avsevärt förbättrat chatbotprestanda. Genom att utnyttja sin djupa bidirektionella kontext kan chatbots generera mer sammanhängande och kontextuellt lämpliga svar, vilket förbättrar användarnöjdhet och engagemang. Företag som Microsoft har integrerat BERT i sina plattformar för konverserande AI, vilket möjliggör mer naturliga och effektiva interaktioner inom kundservice och virtuella assistentapplikationer.
Utöver sökning och chatbots har BERT:s arkitektur anpassats för uppgifter som känsloanalys, dokumentklassificering och frågesvar. Dess förmåga att finjusteras för specifika uppgifter med relativt små datamängder har demokratiserat tillgången till NLP av högsta kvalitet, vilket gör att organisationer av alla storlekar kan implementera avancerad språkförståelse. Som ett resultat fortsätter BERT att driva innovation inom olika industrier, från hälso- och sjukvård till finans, genom att möjliggöra att maskiner kan bearbeta och tolka mänskligt språk med en oöverträffad noggrannhet och nyans.
Begränsningar och Utmaningar: Där BERT Faller Kort
Trots sin transformerande inverkan på naturlig språkbehandling uppvisar BERT flera märkbara begränsningar och utmaningar. En primär oro är dess beräkningsintensitet; både förträning och finjustering av BERT kräver betydande hårdvaruresurser, vilket gör det mindre tillgängligt för organisationer med begräsad beräkningsinfrastruktur. Modellens stora storlek leder också till hög minnesanvändning och långsammare inferenstider, vilket kan hindra användningen i realtid eller resursbegränsade miljöer (Google AI Blog).
BERT:s arkitektur är inneboende begränsad till fasta längder på inmatningssekvenser, vanligtvis begränsade till 512 token. Denna begränsning utgör utmaningar för uppgifter som involverar längre dokument, eftersom avkortning eller komplexa uppdelningsstrategier krävs, vilket potentiellt leder till förlust av kontext och försämrad prestanda (arXiv). Dessutom är BERT förtränad på stora, allmänna domänkorpor, vilket kan leda till suboptimal prestanda på domänspecifika uppgifter om ytterligare domänanpassning inte utförs.
En annan utmaning är BERT:s oförmåga att utföra resonemang eller hantera uppgifter som kräver världs kunskap bortom vad som finns i dess träningsdata. Modellen är också mottaglig för adversariella attacker och kan producera partiska eller nonsensiska utdata, vilket återspeglar fördomar som finns i dess träningsdata (National Institute of Standards and Technology (NIST)). Dessutom förblir BERT:s tolkbarhet begränsad, vilket gör det svårt att förstå eller förklara dess förutsägelser, vilket är en betydande oro för applikationer inom känsliga områden som hälso- och sjukvård eller juridik.
BERTs Framtid: Innovationer, Varianter och Vad som Kommer Näst
Sedan introduktionen har Bidirectional Encoder Representations från Transformers (BERT) revolutionerat naturlig språkbehandling (NLP), men området fortsätter att utvecklas snabbt. Framtiden för BERT formas av pågående innovationer, framkomsten av många varianter och integrationen av nya tekniker för att hantera dess begränsningar. En stor riktning är utvecklingen av mer effektiva och skalbara modeller. Till exempel erbjuder modeller som DistilBERT och TinyBERT lätta alternativ som behåller mycket av BERT:s prestanda samtidigt som de minskar beräkningskraven, vilket gör dem lämpliga för användning på edge-enheter och i realtidsapplikationer (Hugging Face).
En annan betydande trend är anpassningen av BERT för flerspråkiga och domänspecifika uppgifter. Flerspråkiga BERT (mBERT) och modeller som BioBERT och SciBERT är skräddarsydda för specifika språk eller vetenskapliga domäner, vilket demonstrerar BERT-arkitekturens flexibilitet (Google AI Blog). Dessutom fokuserar forskning på att förbättra BERT:s tolkbarhet och robusthet, vilket adresserar oro om modelltransparens och sårbarheter för adversariella attacker.
Ser vi framåt, är integrationen av BERT med andra modaliteter, såsom vision och tal, ett lovande område, som vi kan se i modeller som VisualBERT och SpeechBERT. Dessutom har framväxten av storskaliga förtränade modeller, som GPT-3 och T5, inspirerat hybrida arkitekturer som kombinerar styrkorna i BERT:s bidirektionella kodning med generativa kapabiliteter (Google AI Blog). Allt eftersom forskningen fortsätter, förväntas BERT och dess efterträdare spela en central roll i att främja AI-systemens kapabiliteter över olika tillämpningar.
Källor & Referenser
- Google AI Language
- Vaswani et al. (2017)
- Google Research
- National Institute of Standards and Technology (NIST)
- Hugging Face