Znotraj BERT: Kako bi-directional encoder reprezentacije iz transformatorjev preoblikujejo obdelavo naravnega jezika in poganjajo naslednjo generacijo aplikacij umetne inteligence
- Uvod v BERT: Izvor in preboji
- Kako BERT deluje: Znanost za bidirekcionalnimi transformatorji
- Predusposabljanje in fino prilagajanje: BERT-ov dvo-stopenjski učni proces
- BERT proti tradicionalnim modelom NLP: Kaj ga loči?
- Praktične uporabe: BERT v iskanju, klepetalnih robotih in drugje
- Omejitve in izzivi: Kje BERT ne uspe
- Prihodnost BERT: Inovacije, varianti in kaj sledi
- Viri in reference
Uvod v BERT: Izvor in preboji
Bidirectional Encoder Representations from Transformers (BERT) predstavlja pomemben mejnik v evoluciji obdelave naravnega jezika (NLP). Uveden s strani raziskovalcev na Google AI Language leta 2018, je BERT temeljito spremenil način, kako stroji razumejo jezik, tako da izkoriščajo moč globokih bidirekcionalnih transformatorjev. V nasprotju s prejšnjimi modeli, ki so obdelovali besedilo od leve proti desni ali od desne proti levi, arhitektura BERT omogoča, da hkrati upošteva celoten kontekst besede, tako da gleda na njeno levo in desno okolje. Ta bidirekcionalni pristop omogoča bolj odtenčeno razumevanje jezika, zajemajoč subtilne odnose in pomene, katerih enodiriktivni modeli pogosto ne opazijo.
Izvor BERT temelji na arhitekturi transformatorjev, ki so jih prvič predstavili Vaswani et al. (2017), ki zanašajo na mehanizme samopozornosti za obdelavo vhodnih zaporedij hkrati. S predusposabljanjem na ogromnih korpusih, kot sta Wikipedia in BooksCorpus, se BERT uči splošne jezikovne reprezentacije, ki jih je mogoče fino prilagoditi za širok spekter nalog, vključno z odgovarjanjem na vprašanja, analizo čustev in prepoznavanjem poimenovanih entitet. Izdaja BERT je postavila nove standarde v več nalogah NLP, presegla prejšnje vrhunske modele in spodbudila val raziskav v arhitekturah, temelječih na transformatorjih.
Preboji, ki jih je dosegel BERT, niso le napredovali akademsko raziskovanje, temveč so tudi privedli do praktičnih izboljšav v komercialnih aplikacijah, kot so iskalniki in virtualni asistenti. Njegova odprtokodna izdaja je demokratizirala dostop do močnih jezikovnih modelov, kar je spodbujalo inovacije in sodelovanje v skupnosti NLP.
Kako BERT deluje: Znanost za bidirekcionalnimi transformatorji
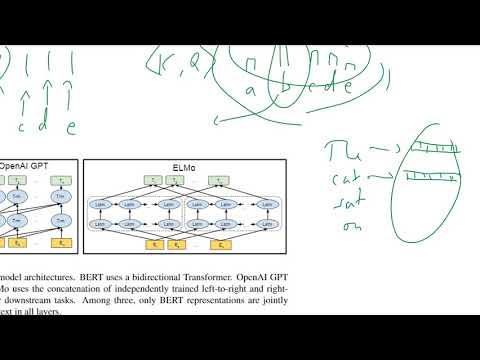
Osnovna inovacija BERT leži v njegovem uporabljanju bidirekcionalnih transformatorjev, ki temeljito spremenijo, kako jezikovni modeli razumejo kontekst. V nasprotju s tradicionalnimi modeli, ki obdelujejo besedilo ali od leve proti desni ali od desne proti levi, BERT izkorišča arhitekturo transformatorjev za analizo vseh besed v stavku hkrati, pri čemer upošteva tako prejšnje kot naslednje besede. Ta bidirekcionalni pristop omogoča BERT-u, da zajame odtenčne odnose in odvisnosti znotraj jezika, kar vodi do globljega razumevanja pomena in konteksta.
Znanost za BERT-ovo bidirekcionalnost je zakoreninjena v njegovih nalogah predusposabljanja: Masked Language Modeling (MLM) in Next Sentence Prediction (NSP). V MLM so naključne besede v stavku zakrite, model pa se uči napovedovati te zakrite tokene, pri čemer upošteva celoten kontekst na obeh straneh. To se razlikuje od prejšnjih modelov, ki so lahko uporabljali le delni kontekst, kar je omejevalo njihovo razumevanje. NSP pa BERT-u omogoča, da razume odnos med pari stavkov, kar dodatno izboljšuje njegovo razumevanje konteksta in koherence.
BERT-ova arhitektura temelji na transformatorjevem kodirniku, ki uporablja mehanizme samopozornosti za vrednotenje pomembnosti vsake besede v razmerju do drugih v vhodnem besedilu. To BERT-u omogoča modeliranje kompleksnih jezikovnih pojavov, kot so polisemija in dolgoročne odvisnosti. Rezultat je model, ki dosega vrhunsko zmogljivost na širok spekter nalog obdelave naravnega jezika, vključno z odgovarjanjem na vprašanja in analizo čustev. Za podroben tehnični pregled se sklicujte na izvirni članek Google AI Language in uradno dokumentacijo Google Research.
Predusposabljanje in fino prilagajanje: BERT-ov dvo-stopenjski učni proces
Izjemna zmogljivost BERT-a pri nalogah obdelave naravnega jezika je večinoma posledica njegovega inovativnega dvo-stopenjskega učnega procesa: predusposabljanje in fino prilagajanje. Med fazo predusposabljanja je BERT izpostavljen velikim količinam neoznačenega besedila ter se uči splošne jezikovne reprezentacije skozi dve nalogi, samonadzorovano: Masked Language Modeling (MLM) in Next Sentence Prediction (NSP). V MLM so naključne besede v stavku zakrite, model pa se uči napovedovati te zakrite tokene na podlagi njihovega konteksta, kar omogoča globoko bidirekcionalno razumevanje. NSP, po drugi strani, BERT-u omogoča, da ugotovi, ali en stavek logično sledi drugemu, kar je ključnega pomena za naloge, ki vključujejo odnose med stavki (Google Research).
Po predusposabljanju BERT preide na fino prilagajanje na specifičnih nalogah, kot so odgovarjanje na vprašanja, analiza čustev ali prepoznavanje poimenovanih entitet. V tej fazi je predusposobljen model dodatno treniran na manjšem, označenem naboru podatkov, prilagojenem ciljni nalogi. Arhitektura ostane večinoma nespremenjena, toda po potrebi se dodajo specifične plasti naloge (npr. klasifikacijske glave). Fino prilagajanje običajno zahteva le nekaj epoh in razmeroma malo podatkov, saj je model med predusposabljanjem že pridobljen robustno razumevanje jezika. Ta dvo-stopenjski pristop omogoča BERT-u, da doseže vrhunske rezultate na širokem spektru merilnikov NLP, kar dokazuje učinkovitost prenosa učenja v jezikovnih modelih (Google AI Blog).
BERT proti tradicionalnim modelom NLP: Kaj ga loči?
BERT (Bidirectional Encoder Representations from Transformers) predstavlja pomembno odstopanje od tradicionalnih modelov obdelave naravnega jezika (NLP), predvsem zaradi svojega razumevanja bidirekcionalnega konteksta in arhitekture, temelječe na transformatorjih. Tradicionalni modeli NLP, kot so vreča besed, n-gram modeli in prejšnje embeding besed, kot sta Word2Vec ali GloVe, običajno obdelujejo besedilo na enodiriktiven ali kontekstno neodvisen način. Na primer, modeli, kot je Word2Vec, generirajo vektorske predstavitve besed izključno na podlagi lokalnih kontekstualnih oken, ponavljajoče nevronske mreže (RNN) pa obdelujejo zaporedja od leve proti desni ali od desne proti levi, kar omejuje njihovo sposobnost zajemanja celotnega konteksta stavka.
V nasprotju s tem BERT izkorišča arhitekturo transformatorjev, ki mu omogoča, da hkrati upošteva tako levo kot desno kontekst za vsako besedo v stavku. Ta bidirekcionalni pristop omogoča BERT-u, da generira bogatejše, kontekstualno občutljive reprezentacije besed, kar je še posebej prednostno za naloge, ki zahtevajo odtenčeno razumevanje, kot so odgovarjanje na vprašanja in analiza čustev. Poleg tega je BERT predusposoben na velikih korpusih z uporabo ciljev maske in napovedovanja naslednjega stavka, kar mu omogoča, da se nauči globokih semantičnih in sintaktičnih značilnosti, preden se fino prilagodi specifičnim nalogam.
Empirični rezultati so pokazali, da BERT dosledno prehiteva tradicionalne modele v širokem spektru merilnikov NLP, vključno z nizoma GLUE in SQuAD. Njegova arhitektura in učni paradigmi sta postavila nove standarde za prenos učenja v NLP, kar omogoča izvajalcem, da dosežejo vrhunske rezultate z minimalnimi spremembami specifične arhitekture naloge. Za več podrobnosti se sklicujte na izvirni članek Google AI Language in uradno BERT GitHub repozitorij.
Praktične uporabe: BERT v iskanju, klepetalnih robotih in drugje
Transformativni vpliv BERT-a na obdelavo naravnega jezika (NLP) je najbolj očiten v njegovih praktičnih aplikacijah, zlasti v iskalnikih, klepetalnih robotih in številnih drugih področjih. V iskanju BERT omogoča sistemom, da bolje razumejo kontekst in namen za uporabniškimi poizvedbami, kar vodi do bolj relevantnih in natančnih rezultatov. Na primer, Google je integriral BERT v svoje iskalne algoritme, da bi izboljšal interpretacijo konverzacijskih poizvedb, še posebej tistih, ki vključujejo predloge in odtenčne fraze. Ta napredek omogoča iskalnikom, da združijo poizvedbe z vsebino na način, ki bolj natančno odraža človeško razumevanje.
Na področju konverzacijske umetne inteligence je BERT znatno izboljšal zmogljivost klepetalnih robotov. Z izkoriščanjem njegovega globokega bidirekcionalnega konteksta lahko klepetalni roboti generirajo bolj koherentne in kontekstualno primerne odgovore, kar izboljša zadovoljstvo in angažiranost uporabnikov. Podjetja, kot je Microsoft, so vključila BERT v svoje platforme konverzacijske umetne inteligence, kar omogoča bolj naravne in učinkovite interakcije v aplikacijah za pomoč strankam in virtualne asistente.
Poleg iskanja in klepetalnih robotov se je arhitektura BERT prilagodila za naloge, kot so analiza čustev, klasifikacija dokumentov in odgovarjanje na vprašanja. Njegova sposobnost, da se fino prilagodi specifičnim nalogam z razmeroma manjšimi nabori podatkov, je demokratizirala dostop do vrhunskih NLP, kar omogoča organizacijam vseh velikosti, da uvedejo napredne zmožnosti razumevanja jezika. Posledično BERT še naprej spodbuja inovacije v različnih industrijah, od zdravstvene oskrbe do financ, tako da omogoča strojem, da obdelujejo in interpretirajo človeški jezik s prej nevideno natančnostjo in odtenki.
Omejitve in izzivi: Kje BERT ne uspe
Kljub svojemu transformativnemu vplivu na obdelavo naravnega jezika BERT izkazuje več opaznih omejitev in izzivov. Ena glavnih skrbi je njegova računalniška intenzivnost; tako predusposabljanje kot fino prilagajanje BERT-a zahtevata pomembne računalniške vire, kar ga dela manj dostopnega za organizacije z omejeno računalniško infrastrukturo. Velikost modela prav tako vodi v visoko porabo pomnilnika in počasnejši čas sklepanja, kar lahko ovira uvedbo v realnem času ali v okoljih z omejenimi viri (Google AI Blog).
BERT-ova arhitektura je inherentno omejena na vhodne zaporedje fiksne dolžine, ki je običajno omejeno na 512 tokene. Ta omejitev predstavlja izzive za naloge, ki vključujejo daljše dokumente, saj so potrebne trunciranje ali kompleksne strategije razdeljevanja, kar lahko vodi do izgube konteksta in poslabšanja zmogljivosti (arXiv). Poleg tega je BERT predusposoben na velikih, splošno usmerjenih korpusih, kar lahko privede do suboptimalne zmogljivosti pri nalogah, specifičnih za določeno področje, razen če se izvede dodatno prilagajanje domeni.
Drug izziv je BERT-ova nezmožnost izvajanja sklepanja ali obravnave nalog, ki zahtevajo svetovno znanje, ki presega tisto, kar je prisotno v njegovih podatkih za usposabljanje. Model je prav tako dovzeten za napade, ki so osnovani na zavajanju, in lahko proizvede pristranske ali nesmiselne izhode, kar odraža pristranskosti, prisotne v njegovih podatkih za usposabljanje (Nacionalni inštitut za standarde in tehnologijo (NIST)). Poleg tega ostaja interpretabilnost BERT-a omejena, kar otežuje razumevanje ali razlago njegovih napovedi, kar je pomembna skrb za aplikacije v občutljivih področjih, kot sta zdravstvo ali pravo.
Prihodnost BERT: Inovacije, varianti in kaj sledi
Od njegove uvedbe je Bidirectional Encoder Representations from Transformers (BERT) revolucioniral obdelavo naravnega jezika (NLP), vendar se področje še naprej hitro razvija. Prihodnost BERT-a je oblikovana z nadaljnjimi inovacijami, nastankom številnih variant in integracijo novih tehnik za reševanje njegovih omejitev. Ena glavnih smernic je razvoj bolj učinkovitih in razširljivih modelov. Na primer, modeli, kot sta DistilBERT in TinyBERT, ponujajo lahke alternative, ki ohranjajo veliko BERT-ove zmogljivosti, hkrati pa zmanjšujejo računalniške zahteve, kar jih naredi primerne za uvedbo na robnih napravah in v aplikacijah v realnem času (Hugging Face).
Drug pomemben trend je prilagoditev BERT-a za večjezične in naloge, specifične za področje. Večjezični BERT (mBERT) in modeli, kot sta BioBERT in SciBERT, so prilagojeni za specifične jezike ali znanstvena področja, kar dokazuje prilagodljivost BERT-ove arhitekture (Google AI Blog). Poleg tega se raziskave osredotočajo na izboljšanje interpretabilnosti in robustnosti BERT-a, s čimer se naslavljajo skrbi glede preglednosti modela in ranljivosti na zavajanje.
Gledajući naprej, integracija BERT-a z drugimi modaliteta, kot sta vid in govor, je obetavna področje, kar se vidi na modelih, kot sta VisualBERT in SpeechBERT. Poleg tega je vzpon modelov, predusposobljenih na večjih lestvicah, kot sta GPT-3 in T5, navdihnil hibridne arhitekture, ki združujejo prednosti BERT-ove bidirekcionalne kodiranja z generativnimi zmožnostmi (Google AI Blog). Ko se raziskave nadaljujejo, se pričakuje, da bosta BERT in njene naslednice igrali osrednjo vlogo pri napredovanju zmožnosti sistemov umetne inteligence v različnih aplikacijah.
Viri in reference
- Google AI Language
- Vaswani et al. (2017)
- Google Research
- Nacionalni inštitut za standarde in tehnologijo (NIST)
- Hugging Face